
Why Your Worst SEO Pages Could Be Your Best AEO Pages (Featuring Eli Schwartz)
Ranking still matters. Everything you did to rank doesn't.

Co-authored with Eli Schwartz, author of Product-Led SEO.
Eli is the author of the book Product-Led SEO and for the last few years has worked as an SEO strategic consultant for some of the largest brands on the internet like LinkedIn, Tinder, Coinbase, Gusto, G2, and many others. He writes a weekly newsletter on the future of SEO and AEO at ProductLedSEO.com, and he advocates for putting the user first in any organic strategy, whether it’s designed for traditional search or new LLMs.
Eli sent me a line last week I haven’t been able to stop thinking about:
“For years I didn’t believe small and local businesses should have websites at all. They didn’t get any traffic. Now they feed the LLMs.”
Read it twice. That’s the entire shift in two sentences.
For a decade, the pages most B2B content teams built were optimized for one thing: aggregate organic traffic. Pages that didn’t drive sessions got deleted. Pages too narrow to rank for a head term never got written. The unranked, the specific, the weird. They got pruned out of every content portfolio I’ve ever audited.
Some of these pages LLMs cite…and cite well.
This isn’t a vibe. AirOps spent the last several months running fan-out analysis across tens of thousands of real ChatGPT responses. They decompose prompts into the sub-queries the model actually retrieves against, then score which pages get cited and which get walked past. It’s the deepest empirical dataset we have on any answer engine. The findings appear to hold directionally across Perplexity, Claude search, and Google AI Overviews based on what teams in the space are seeing but the specifics vary by system and the rest of this piece is grounded in the ChatGPT data unless noted.
The picture is unkind to almost every editorial instinct the SEO industry has spent fifteen years building.
The thesis in one sentence:
Ranking still matters. Everything you did to rank doesn’t.
The mechanism: page becomes passage
Google ranks URLs. Answer engines cite passages. That two-word swap is the whole shift and most of the AEO advice you’ve read is downstream of getting it right.
When ChatGPT answers a question, the model doesn’t fetch your page. It fetches a passage. The pattern across retrieval-augmented systems is broadly the same: pages get chunked into passage windows of a few hundred tokens, each chunk gets scored against the query (typically through some combination of embedding similarity and lexical match), and the top chunks get pulled into the model’s context. The exact pipeline inside ChatGPT, Perplexity, and AI Overviews isn’t fully public and the systems differ in important ways. The directional principle holds across all of them: the unit of value is the passage, not the URL.
Your page’s domain authority gets you indexed. Your page’s ranking gets you retrieved. AirOps found that the first returned result for a fan-out query gets cited 58.4% of the time versus 14.2% for the tenth result, so SEO is still a precondition. Once a chunk enters the retrieval pool, it’s on its own.
Authority becomes local. A single page can be cited for one sub-topic and invisible for the other eleven on the same URL. Page-level signals like internal linking, topical depth, length, and comprehensive coverage don’t transfer cleanly down to the chunk. Every word on the page that isn’t the answer becomes a cost. Each paragraph of adjacent context dilutes the chunk’s relevance to the query that retrieved it.
It’s probably worth naming this.
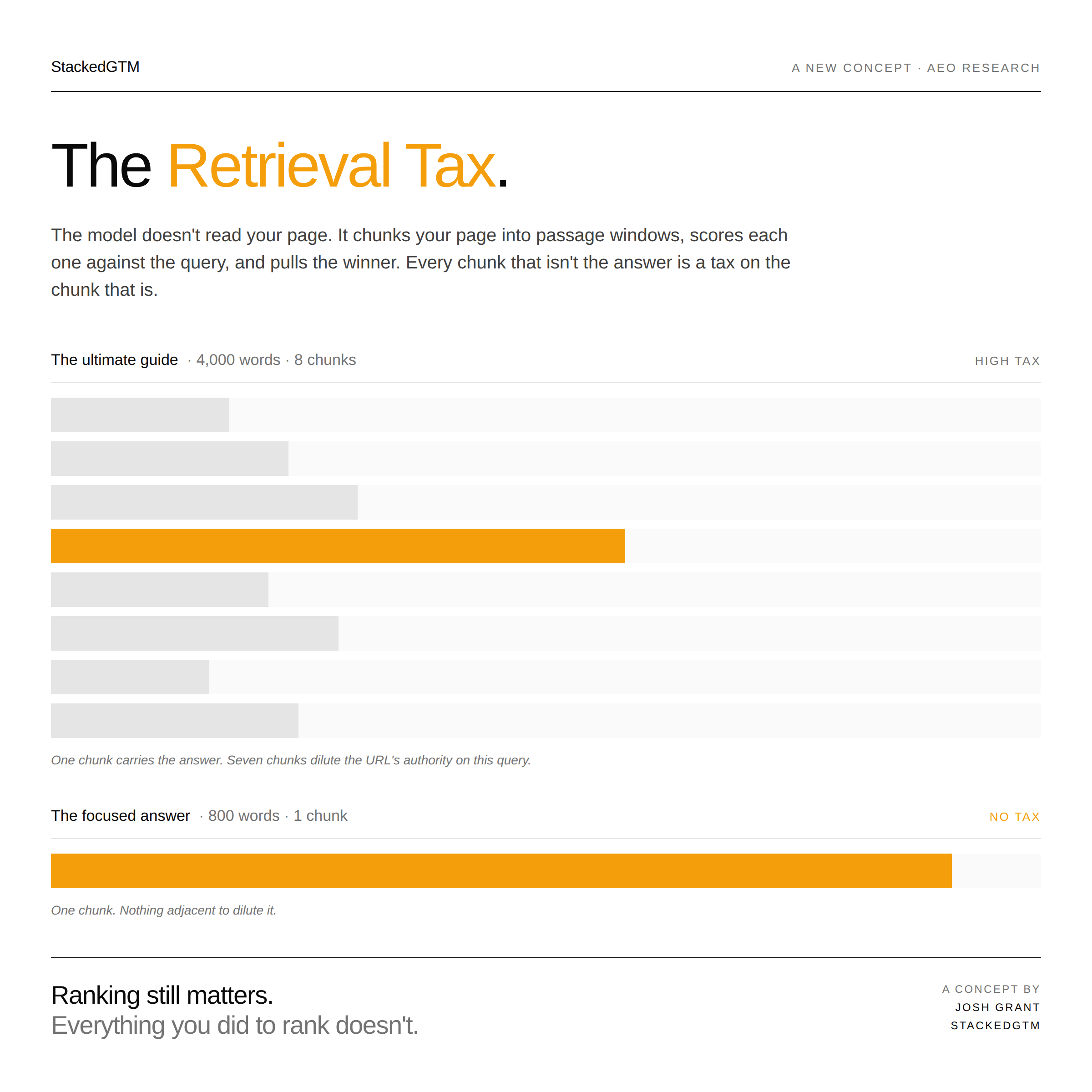
The Retrieval Tax (working name. If you've got something cooler, I'm listening…reply and tell me). Every word on a page that isn’t the answer to the question being retrieved is a tax on the answer’s relevance. Ultimate guides pay the highest retrieval tax in content marketing. Focused answer pages pay almost none.
The AirOps fan-out work measures the tax in citations.
Before the three findings: 95% of the surface is invisible to your keyword tool
One precondition fact. Nothing in the rest of this piece makes sense without it.
The fan-out queries ChatGPT generates when it builds an answer are largely invisible to traditional keyword tools. In the AirOps dataset analyzed by ALM Corp, 95% of fan-out queries had zero monthly search volume in conventional keyword tools. Ahrefs, Semrush, Google Keyword Planner. None of them can see these queries.
The surface of your category is bigger than your keyword tool can see and the invisible part is where citation is decided. If your content strategy is downstream of a keyword tool, you are optimizing for 5% of the actual retrieval surface, and not the 5% that matters most for AEO.
Everything below follows from this.
Finding 1: Domain authority is inversely correlated with citation
Inversely correlated, not uncorrelated. The numbers aren’t subtle.
In the AirOps fan-out dataset, pages that get cited consistently have an average DA of 53. Pages that never get cited have an average DA of 56. The backlink gap is sharper: always-cited pages have around 1.1M backlinks on average; never-cited pages have around 3.2M. A 3x inverse gap. At every level of query match, the lowest DA quartile in the dataset performs as well or better than the highest.
The site-type breakdown is even more telling. The five highest-DA categories in the dataset are YouTube (DA 100), Wikipedia (95), major news (94), Reddit (92), and health publishers (90). Effectively identical authority profiles. Their citation rates range from 2.4% to 59.2%. Twenty-fold difference at essentially identical DA. The signal is somewhere else.
LLMs don’t penalize high-DA pages. The mechanism is more boring than that. The editorial behaviors that maximize DA (comprehensiveness, hedging, generalism, optimizing for head terms) are the same behaviors that maximize the retrieval tax. High DA selects for content that pays the most retrieval tax. The correlation isn’t punitive. It falls out of the mechanism.
This is the finding that breaks the link-building model of enterprise SEO. Links still matter for ranking. They still matter for getting crawled, indexed, and retrieved. The link-building budget that won you DA is no longer the budget that wins you citation, and the reallocation question is genuinely uncomfortable for any team whose marketing org chart has been organized around DA for the last decade.
Eli’s small-business framing is the same point on a different timescale. The local plumber has a DA of 12. He’s not in the link-building game. He’s also written the single most specific page on the internet about a P-trap, because it’s the only thing he was qualified to write about. The model picks his page over Wikipedia’s, not despite his DA but in part because of what high DA correlates with at the page level.
Finding 2: Ultimate guides bury the answer
A 4,000-word ultimate guide is an SEO masterpiece. For passage retrieval, it is a disaster.
Here’s why. The retrieval system chunks the guide into passage windows. The user’s question is narrow. The chunk containing your answer also contains hundreds of words about tangentially related topics, so its relevance score against the specific fan-out query that retrieved it gets diluted by the surrounding noise. A competing page that runs 800 words on one question chunks into a single window whose content sits much closer to the query. The model picks it.
AirOps shows this empirically. When primary query relevance is high, focused pages around 800 words outperform comprehensive guides at 5,000+. SparkToro covered the same finding under the right headline: the death of the ultimate guide. That framing is correct. Not “the difficulty of the ultimate guide.” Not “the new constraints on the ultimate guide.” The death of it.
Most enterprise content portfolios have spent the last five years consolidating narrow pages into hub guides because hubs ranked. Atomization, the opposite move, is what wins for citation. If you’ve spent the last two years consolidating, you’ve spent the last two years building the wrong asset for what’s coming next.
That’s not a comfortable sentence. It’s the sentence the data forces.
Finding 3: 26 to 50 percent subtopic coverage beats 100 percent
This one gives you a planning heuristic, which makes it the most operationally useful finding in the AirOps work.
For any seed query, the fan-out process expands into a set of sub-questions the model uses to assemble its answer. You can score any candidate page on how much of that sub-question set it addresses and how strong its primary query match is. When primary match is strong, citation rate peaks at 26 to 50 percent sub-topic coverage, then falls off above it. Pages that try to cover everything get cited less than pages that own a defined slice.
A page that owns three sub-questions definitively gets cited three times. A page that touches twelve sub-questions superficially gets cited zero.
This retires the keyword map as a content planning artifact. In its place: a sub-question map. Enumerate the questions in your category. Pick the 26 to 50 percent slice where you have practitioner authority, proprietary data, or a differentiated point of view. Build one page per sub-question. Abandon the rest.
The pages you don’t write are as strategic as the ones you do. Probably more.
What Eli sees in client work
1) An ecommerce page that never received a lot of search traffic because it was on a highly competitive search term, but is now seeing outsized clicks because it is featured in LLMs.
2) Commoditized product review content that no longer receives many clicks despite high rankings in search, but it leads to brand mentions in LLMs that likely, but can’t be proven, drives brand traffic.
3) On a personal level, when prospective clients reach out and say they found him on an LLM, he always asks for the prompt, and typically, the source citation that led to an LLM mention is on a page that might never have seemed like a good source. Examples include podcast show notes pages, bios from many years ago at conferences, or media mentions.
4) A client whose primary product was classified listings rearchitected their AEO strategy to have their local classified pages be mentioned as a source for users to find. These pages never really ranked in organic search, but now they are far more relevant because they are mid-funnel for LLM users.
5) Companies that have specifically doubled down on LLM-only content, with the expectation that they were going to get cited, didn’t see the results they wanted because they didn’t think through their whole user journey.
The playbook, asymmetric on purpose
The to-do list isn’t subtle. It’s also not symmetric. One of these moves matters more than the rest.
The big one: atomize. Audit your top 25 pages by historical SEO performance. Identify every page that contains more than one answerable question. Most will contain five to fifteen. For each answer that earns its own page, spin it out to a dedicated URL whose title is the question. Keep the original as a hub if it earns its keep on rankings, but the answers themselves need to live alone, with their own chunks and their own retrieval surface. Atomization isn’t free. It reshuffles internal linking, redistributes authority across more URLs, and creates cannibalization risk if the new pages aren’t differentiated enough. For priority topics where citation share is the actual goal, the gains outweigh the costs. For your weak-performing long tail, leave the guide alone. This is the move that takes a quarter and pays for the next two years. Nothing else on this list matters as much.
Specialize. Pick the 26 to 50 percent of your category’s sub-questions you can own deeply. Abandon the rest.
The Deletion Audit. This is the inversion of every content audit you’ve ever run. Pull the list of pages your team has flagged for sunset: low traffic, narrow topic, weird angle, no internal links, dead in Google. Filter for the ones that are still factually current and well-written. Then ask one question of each: is this the best answer to a specific question on the internet? The ones where the answer is yes are not sunsets. They are your AEO portfolio, hiding in plain sight because the SEO audit framework you inherited can’t see them. Most teams will find five to twenty pages they were about to delete that are quietly the best assets in their portfolio. Stop deleting them. Start linking to them.
Title-Query Convergence. The cleanest unilateral move on the list. The ALM Corp analysis of AirOps’ data found pages with 50%+ title-to-query word overlap get cited at 20.1%. Pages below 10% overlap get cited at 9.3%. A 2.2x lift driven entirely by what’s in your title tag. The actionable version: on narrow answer pages, your title should be the question, not a clever framing of the question. “How do I revoke an API key” beats “The Complete Guide to API Key Management” every time on a single-question page. Hub pages and category pages need a different titling approach because they still have to serve broader keyword rankings, so this is a tactic for the atoms, not for everything. Most teams haven’t made the move on their atoms because clever titling is what content marketers were trained to do. Untrain it where it costs you citations.
Measure citation, not rank. Pick a citation tracking tool. Pick a category. Run weekly. If you’re not measuring share of cited sources across ChatGPT, Perplexity, Claude, Gemini, and Google AI Overviews, you are flying blind on the part of the funnel that will be load-bearing by Q4.
One honest caveat before the prediction
Retrieval algorithms move fast. The AirOps findings reflect how ChatGPT was building answers when the data was collected. Six months from now the specifics will shift. The optimal coverage band may move. The DA correlation may compress or invert further. The exact title-overlap thresholds will drift. The numbers are not laws.
The direction is. The shift from page to passage, from comprehensive to specific, from generalist to specialist, from keyword map to sub-question map. Every retrieval system that matters is moving toward more of all of these, not less. Anyone betting against atomization, specificity, or measurable citation share is betting against where every answer engine is heading. The numbers will move. The direction won’t.
What I’d put money on
By the end of 2026, the ultimate guide stops being the default unit of B2B content (slightly sad here as a fan/reader/writer of long-form content). The hub-and-spoke model doesn’t disappear but it loses its position as the answer to every brief. The platforms that sold teams on hub-and-spoke are already pivoting. The risk isn’t with them. The risk is with the thousand B2B content shops that built their playbooks on top of those platforms and haven’t pivoted yet. They will either rebuild around answer atoms or they will lose meaningful share in the AEO surface of their categories.
The model rewards specificity. The model penalizes comprehensiveness. The model is the distribution system now.
Eli’s plumber didn’t know any of this. He just wrote the most specific page on the internet about a P-trap because that’s the only thing he was qualified to write about. The model found him.
The question isn’t whether the plumber was right. The question is whether your team can deliberately reproduce, at scale, across an enterprise content portfolio, in the next two quarters, what he did by accident.
Josh Grant and Eli Schwartz
Josh Grant is the founder of StackedGTM.AI and writes the Weekly Operator Brief. Eli Schwartz is the author of Product-Led SEO. Subscribe to his newsletter to stay on the cutting edge of SEO & AEO productledseo.com.
Data in this piece is drawn from AirOps’ fan-out research (The Fan-Out Effect, The Long Tail), ALM Corp’s analysis of the AirOps dataset, and SparkToro’s coverage. The retrieval mechanism descriptions reflect the standard pattern across retrieval-augmented systems and are not specific assertions about any one platform’s pipeline.