
The llms.txt argument is the wrong argument
Google published two statements that look like a contradiction. They aren't. Here is what the file actually does, what my testing showed, and where the real agentic work lives.

I’ve had over a dozen people send me two screenshots and asks which Google to believe.
One is from recent Google’s generative-AI guidance. It puts llms.txt on the list of things you can stop fussing over, next to a reminder that you do not need special files or markup to appear in AI search. The other is from Chrome’s Lighthouse documentation, published within days of the first. It calls llms.txt an emerging convention for LLMs and agents and notes that without it, agents may spend more time crawling a site to work out its structure.
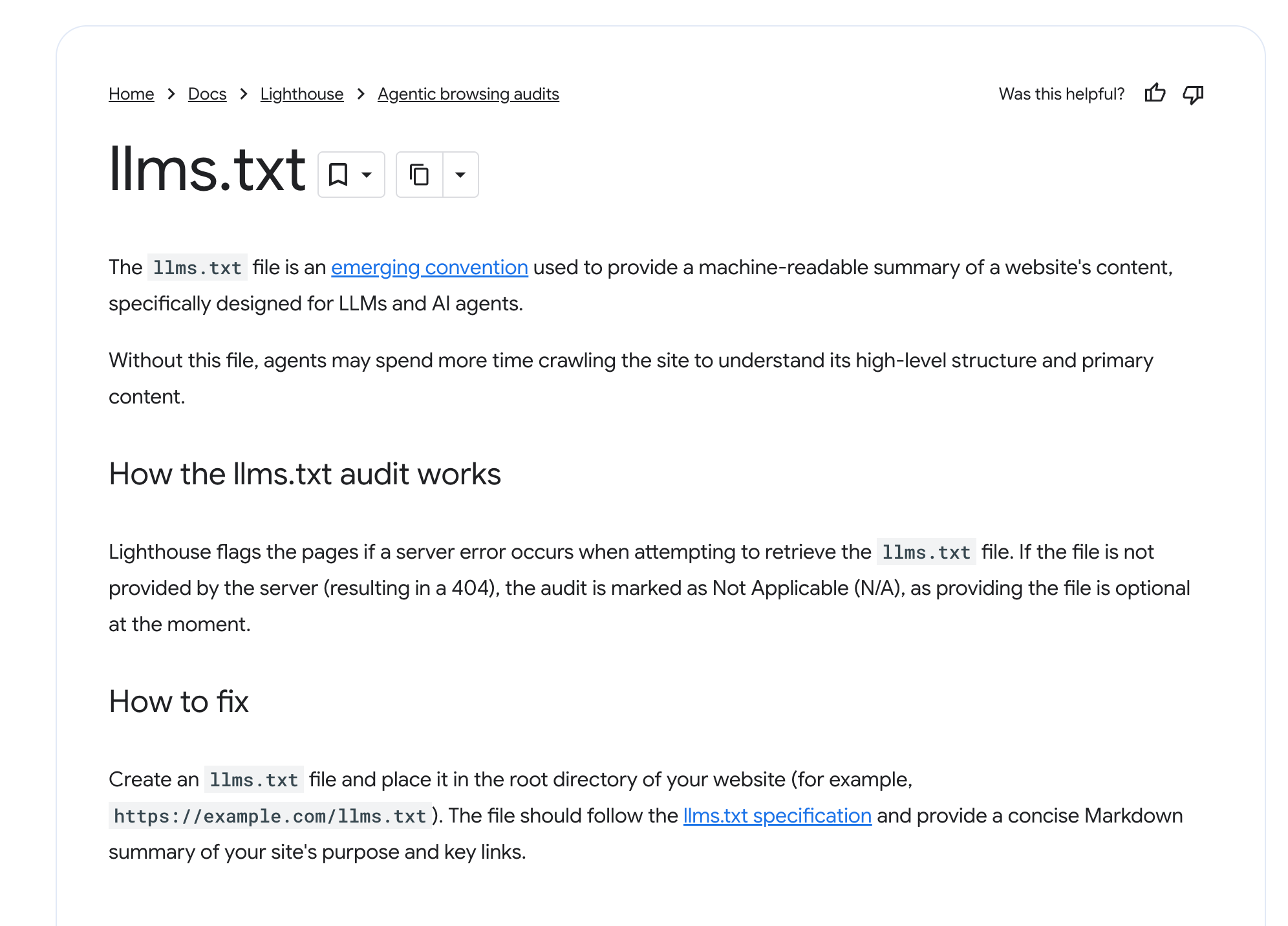
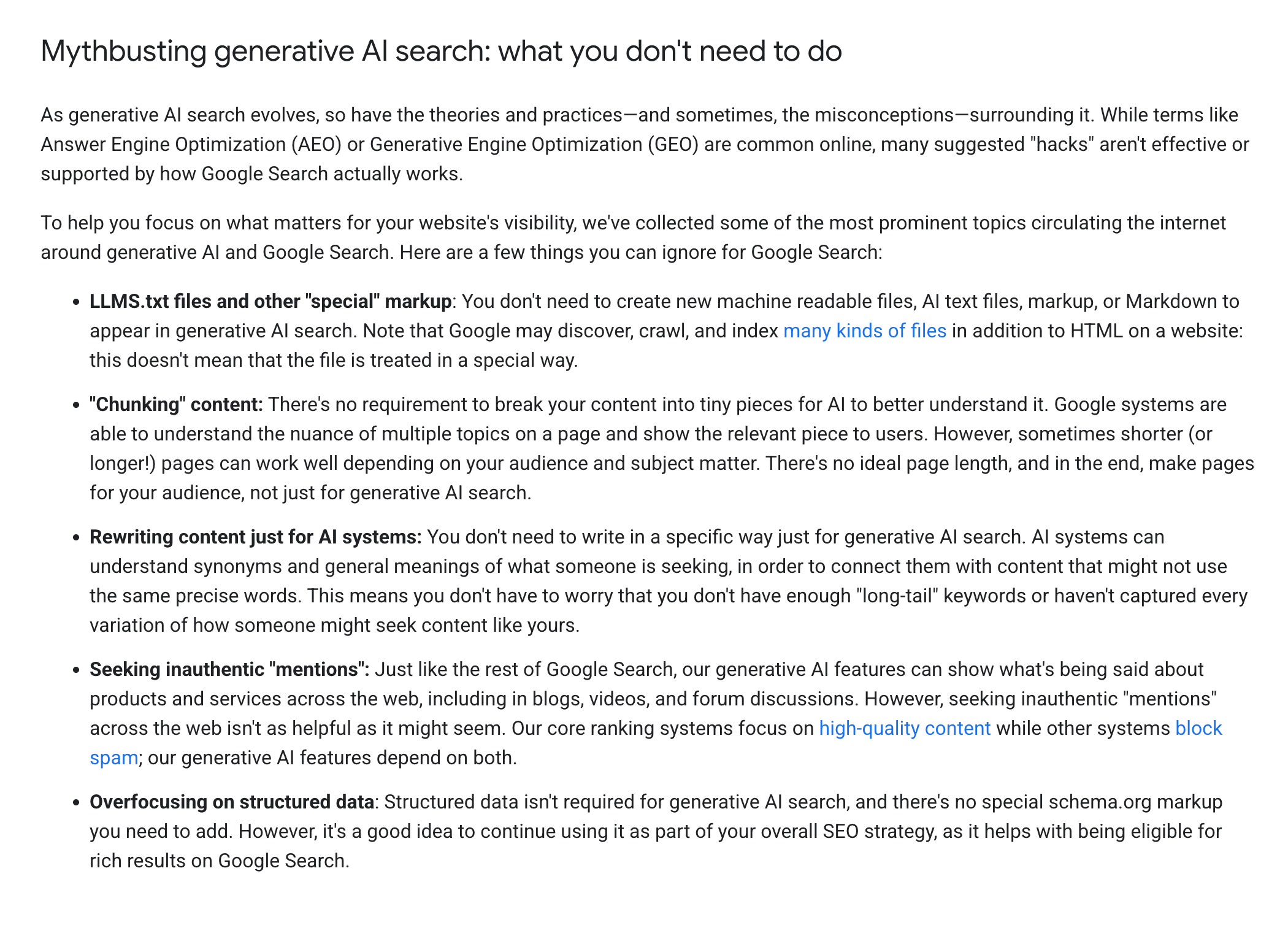
So one team tells you the file does nothing, and another team ships an audit that checks whether you have it. Same logo, same month. Read only the headlines and it looks like a company arguing with itself.
But…the two statements describe two different jobs. The conversation online went sideways because we keep folding both jobs into one flat word, “AI,” and then act surprised when the advice points in two directions.
Here is the distinction that settles it.
Discovery and functionality are not the same job
When Lily Ray put the question to John Mueller (Google) directly on Bluesky, his answer was the most useful thing said on the topic all month, and I would read the whole thread before forming a take.
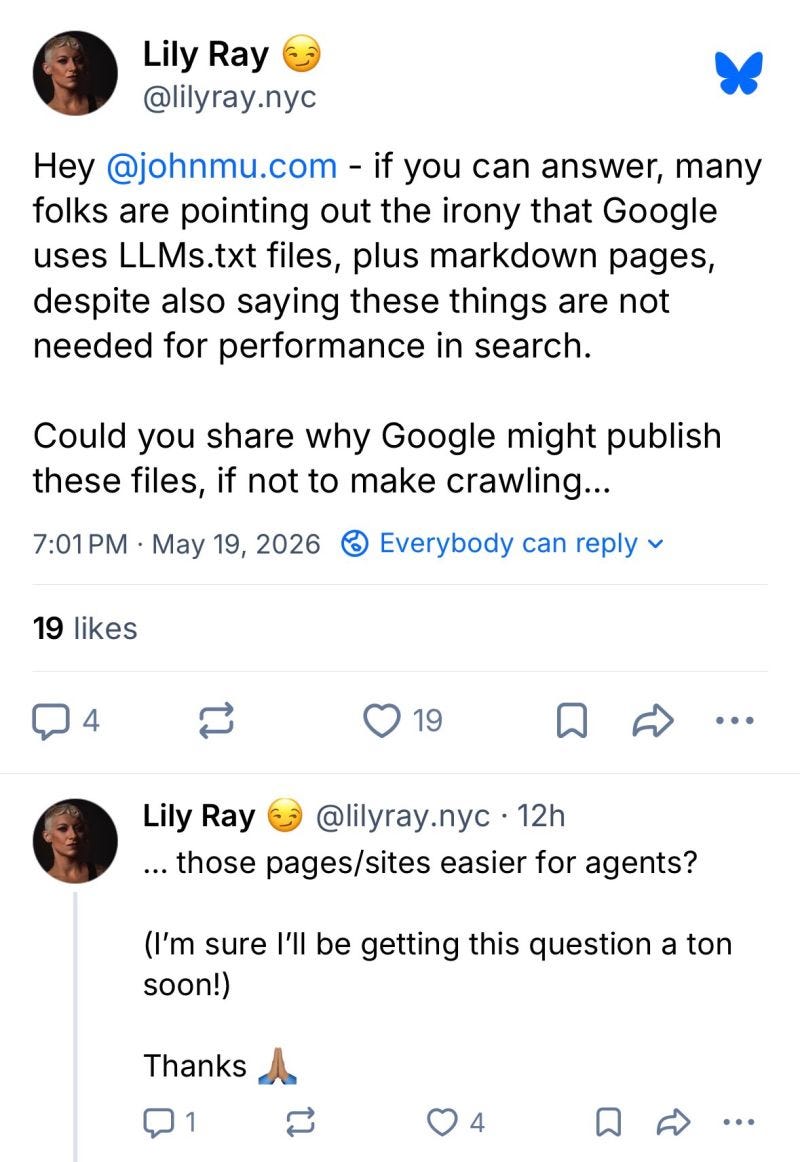
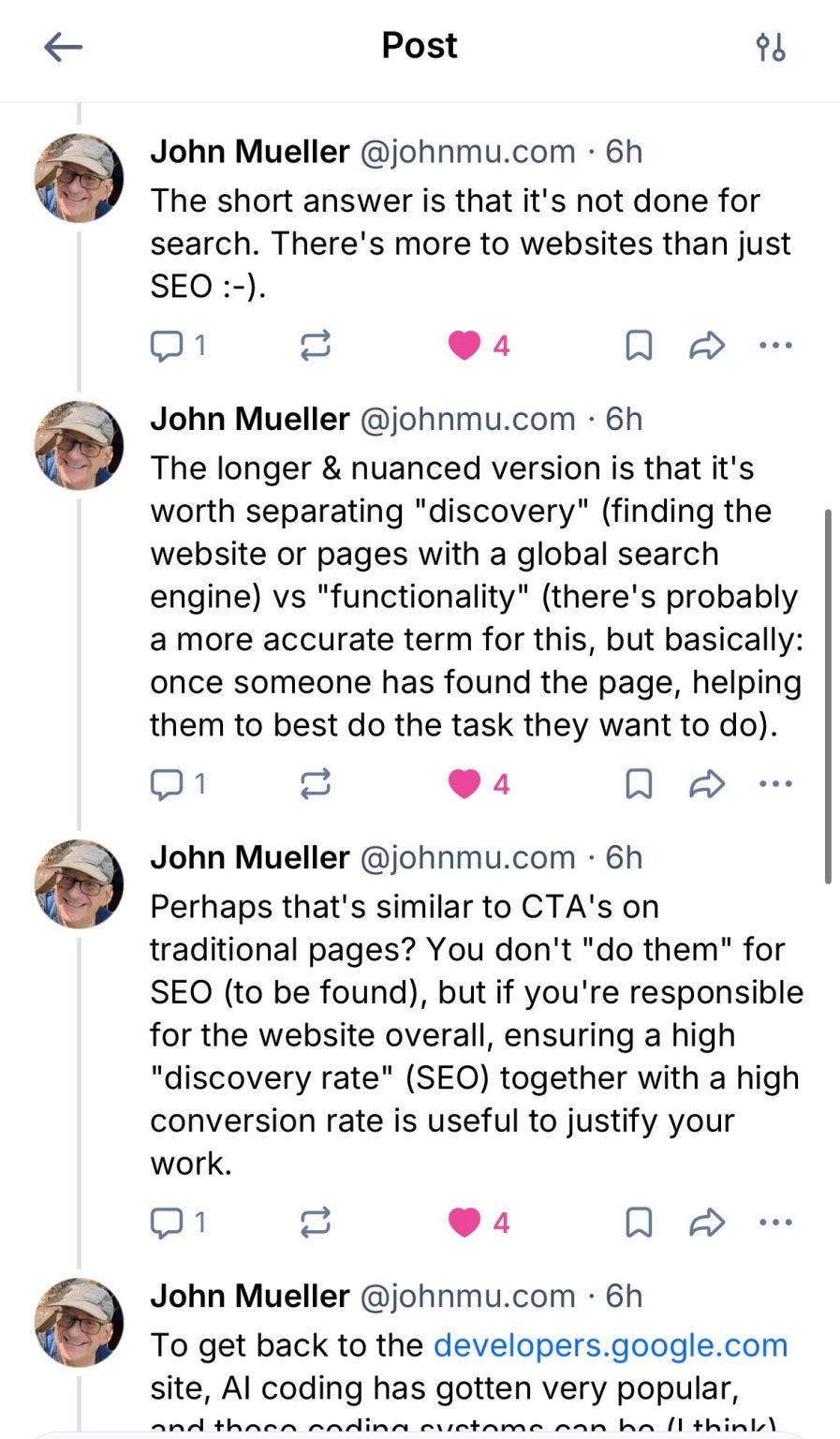
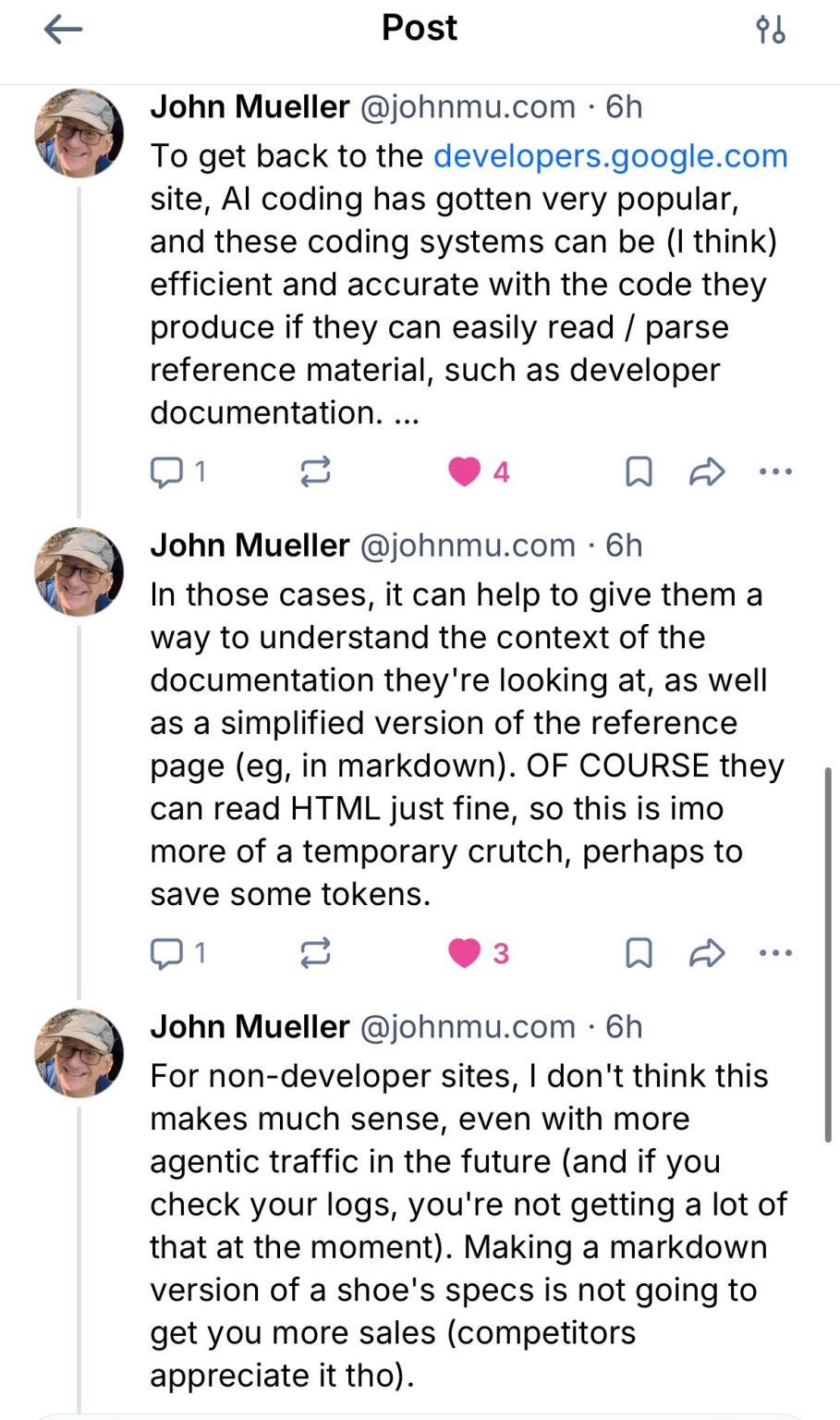

The short version: the llms.txt files sitting on Google’s own developer properties are not there for search. Mueller split the question into discovery and functionality. Discovery is getting found by a global search engine. Functionality is what happens after the find, when a person or an agent is already on your page and trying to finish something. He compared it to a call to action. You do not add a CTA to rank. You add it because once someone arrives, you want them to convert. Both matter to whoever owns the site’s outcomes. They are simply different problems that call for different tools.
llms.txt lives on the functionality side. It was never a discovery lever, which is exactly why a search team can tell you to ignore it for rankings while a browser team finds it mildly useful for agents mid-task. Both statements are true because they are answering different questions.
Mueller went further, and this is the part most of the hot takes skipped. The place llms.txt actually pulls weight today is developer documentation read by AI coding tools. Handing a coding assistant a simplified, low-token version of a reference page can make it faster and more accurate. He was careful to frame it as a stopgap, since those tools read HTML perfectly well on their own. For anything that is not developer docs, he was blunt: it does not make much sense yet, agentic traffic is still a trickle (his advice was to go check your own logs), and a Markdown copy of a shoe’s spec sheet is not going to sell more shoes. His closing line is the one I keep coming back to. Prioritize needs before dreams.
What the broader data says
This is where the marketing internet and the measurable reality stop agreeing.
SE Ranking analyzed roughly 300,000 domains and found no relationship between having an llms.txt file and how often a domain showed up in AI answers. When they removed the file from their model entirely, the model got more accurate, not less. On the consumption side, one log study tracking AI crawlers across ninety days found that out of more than half a billion bot visits, only a few hundred touched llms.txt at all. Adoption sits somewhere around ten percent of sites and climbing, which gives you the real shape of this thing. A lot of people are creating the file, and almost nothing is reading it.
That gap, high creation and near-zero consumption, is the whole story. We are writing a file for an audience that has not shown up.
What I found when I ran it
I do not like arguing about this from the sidelines and I’ve tested this nearly two dozen times in the last 6 months.
Across the sites and pages where I ran before-and-after measurement, I saw no movement I could honestly attribute to the file. No lift in AI citations, no change in how answer engines pulled from the pages, nothing that separated the test set from the control beyond ordinary noise.
I want to be precise about what that does and does not mean. It does not mean the file is harmful. It is cheap to publish and it will not hurt you. It means that if you are shipping llms.txt expecting to appear more often in AI Overviews, ChatGPT, or Perplexity, the expectation is the problem, not your implementation. I wish it were that easy…
Where it actually earns its place
There is a clean rule hiding in all of this.
If you publish developer documentation, ship llms.txt. Coding agents genuinely use it, it is inexpensive to maintain, and the token savings are real. This is the one case where the file does a job nobody else is doing.
If you do not publish developer docs, treat it as optional. Worth knowing that the Lighthouse audit marks the file Not Applicable when it is missing rather than failing you, because providing it is still optional. An audit checkbox is not the same as a result.
The argument worth having instead
The reason the llms.txt fight wears on me is that it is pulling attention away from the part of that same Lighthouse release that actually matters.
The llms.txt check is the least important item in Chrome’s new agentic browsing category. The heavier signals in that category decide whether an agent can read and operate your site at all: a clean accessibility tree, layout that does not shift under an agent’s feet, semantic HTML, and WebMCP, the emerging standard that lets a site expose its functions to an agent directly instead of forcing the agent to guess from a screenshot. WebMCP is heading into a public origin trial in Chrome 149. That is the work that will separate sites an agent can use from sites that merely exist near it.
So when the agentic web does arrive in volume, and the logs say it has not yet, the sites that win will not be the ones that wrote the best text file. They will be the ones an agent can actually navigate and act on.
Discovery is one job. Functionality is another. Spend your scarce hours on the one that is real today, and build the structural pieces that will still matter when the rest catches up.
Needs before dreams.
About StackedGTM
StackedGTM is a media and intelligence platform for go-to-market in the AI era, written by Josh Grant. It’s read by founders, CMOs, and the growth and marketing operators at companies like Anthropic, OpenAI, Stripe, Rippling, Cursor, Webflow, and hundreds more. No BS, no fluff, just deep insights and how-to frameworks on what’s happening in AI GTM.
The newsletter is supported by Profound, the platform serious brands use to measure and act on how they show up across AI search, from tracking citations to running agents against the AEO workflow. That support keeps it independent and free to read. The editorial calls are mine, including the skeptical ones above, and any piece paid for directly is labeled at the top. This one is not.
If you want an operator’s read on where GTM is heading, subscribe.