
The Answer Ownership System
Your market share doesn't protect you in AI search. Your answer share does. Here's the five-agent system that builds it.

WordPress has nearly 60% of the global CMS market. More installs, more backlinks, more domain authority, and more content than any web platform ever built. By every traditional measure of competitive position, it is untouchable.
In 2025, across the buying questions that matter most to someone evaluating a CMS platform, Webflow ranked first in AI-generated answers. WordPress ranked second.
Webflow has 1.3% market share.
When my SEO and AEO team started deploying Profound to track and manage which brands owned the answers across our category, the result stopped me cold. We had spent years building presence inside the web design and dev community, inside the AI-native conversation, inside the modern web discourse. Those signals carry enormous weight with the models synthesizing answers for buyers evaluating platforms. WordPress had dominant volume. We had built relevance in the right places. In the environment that now shapes buying decisions, those are not equivalent advantages.
That inversion is the whole game.
The old moat was built from what you had accumulated: backlinks, brand awareness, content volume. These compounded over years into barriers new entrants could not cross. The new moat is built from what you can consistently maintain: answer presence across the right question clusters, coherent positioning across every surface AI systems index, citation surface area built in the formats models actually pull from.
These also compound over time. But they compound in favor of whoever executes most consistently, not whoever started earliest or spent the most.
A team with the right operational infrastructure can displace a competitor with ten times the content budget, if that competitor is still running the old motion.
Most teams understand this. Almost none can execute it at the pace the environment requires. This piece is about that gap.
Why understanding the strategy is not the same as having one
There is a person on your team, usually whoever owns SEO or content, who manually runs your top buying questions through ChatGPT, Perplexity, and Gemini every few weeks. Who screenshots what comes back. Pastes it into a spreadsheet. Tries to spot patterns, writes a summary, and brings it to a meeting that happens once a month.
By that point the data is three weeks old.
Meanwhile, the answer your competitor is getting cited for has been live for six months. The Reddit thread shaping your category narrative has been indexed for a year. The G2 reviews drifting away from your positioning have been accumulating since last quarter. A comparison page on a third-party site is feeding a version of your differentiation you never approved.
You are doing the work. You are always behind it.
This is the execution collapse nobody names clearly. Not a strategy problem. Not a vision problem. A structural mismatch between the pace at which AI-search environments move and the pace at which manual content operations can respond.
In traditional search, strategy and execution were separable. You wrote the playbook, handed it to a team, and measured performance against it over quarters. In AI search, they are the same thing. Your Answer Ownership strategy is, in practice, whatever your team can consistently execute at the frequency the environment demands.
A team that cannot monitor across five AI interfaces and twelve third-party platforms every week does not have a monitoring strategy. They have a monitoring aspiration. A team that cannot propagate a positioning update across every content surface within days of a messaging shift does not have a consistency strategy. They have a wishlist.
The execution layer is not beneath the strategy. It is the strategy made real, or not made real, depending on whether your team can keep up.
Marketing budgets flatlined at 7.7% of company revenue in 2025. 59% of CMOs report insufficient budget to execute their strategy. The gap is not money. It is operational infrastructure. The teams widening the distance have built systems that monitor, update, synthesize, and distribute at a pace a manual team cannot match. The teams falling behind have not.
Why the urgency is not where most teams are treating it
The share of zero-click searches grew from 56% to 69% in a single year. When AI Overviews appear, organic CTR falls from 1.76% to 0.61%. The top organic result is no longer a traffic guarantee. It is a citation candidate.
The standard response is anxiety about traffic. The more important story is what the traffic arriving from AI search is actually worth.
Ahrefs found that AI search visitors generated 12.1% of signups while accounting for only 0.5% of all traffic. That is a 23x conversion premium over traditional organic. NerdWallet surfaced the same pattern on two consecutive earnings calls: less traffic, more revenue. When their CEO told Morgan Stanley analysts that LLM referral conversion rates were “much higher and growing rapidly,” he was not describing a new channel. He was describing a buyer who arrives post-synthesis, already informed, shortlist already forming.
These buyers are not at the beginning of research. They are at the moment of evaluation. Every surface they encounter needs to be built for that moment. Every surface that is stale, inconsistent, or absent is a gap a competitor fills.
Most teams are measuring a signal, organic traffic, that is structurally declining, while the metric that actually predicts pipeline health goes completely unmeasured.
The metric that replaces traffic
I call it Answer Capture Rate.
Your Answer Capture Rate is the percentage of your highest-revenue buying questions where your brand appears accurately and favorably in the synthesized answer, across the AI interfaces your buyers actually use. Not impressions. Not rankings. Not traffic. The share of the specific answers that form the shortlist a buyer brings to their first sales conversation.
ACR is the metric that replaces organic traffic as the primary indicator of AI search health, because traffic is no longer the mechanism by which most high-intent buyers find you. The mechanism is the answer. If your brand does not appear in the answer, the buyer’s shortlist forms without you, before a single page on your site is ever visited.

Most teams have no idea what their ACR is. They are optimizing for a signal that is structurally declining while the signal that actually predicts pipeline health goes unmeasured. A practical starting point: track 20 to 50 core buying questions across ChatGPT and Perplexity weekly. That is an operational problem, not a measurement one.
The five components below map exactly how to build ACR and maintain it at the pace the environment requires.
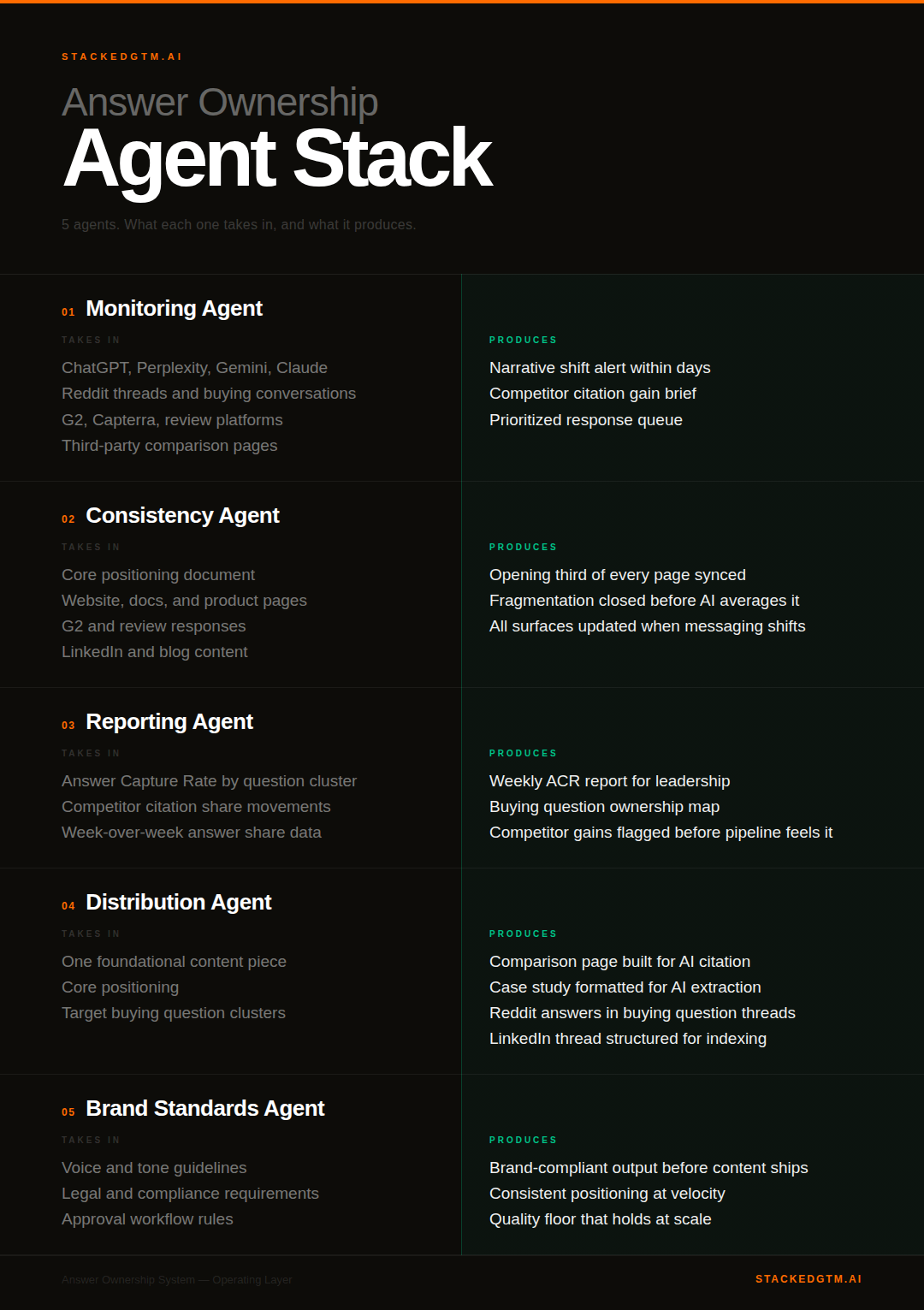
The Answer Ownership System: Five Agents, One Operating Layer
1. Monitoring: Continuous signal across every surface
Answer ownership is not a state you achieve. It is a position you maintain under continuous competitive pressure, across platforms that operate completely independently of each other.
Research from Profound found that only 11% of domains cited by ChatGPT also appear in Perplexity. These are not variations of the same system. They are fundamentally different recommendation engines with different citation behaviors, different source preferences, different update cadences. Monitoring one tells you almost nothing about the others.
Before automated monitoring was in place, narrative shifts surfaced through sales calls. By the time a deal debrief revealed that a buyer had seen a competitor’s framing, the content driving that framing had been live for months. Damage control on positions never known to be lost.
Once a monitoring Agent was watching the category continuously across AI interfaces, Reddit, LinkedIn, and review platforms, a competitor’s comparison page gaining citation share was caught within days of it being indexed. A response was live in a week. The gap between those two timelines is where deals are won or lost.
Response time compresses from months to days. In an environment where AI systems can absorb and reflect a new narrative in weeks, that compression is not an operational detail. It is the difference between owning the answer and chasing it.
Profound’s monitoring Agent runs this watch continuously, not on a schedule, across every AI interface, Reddit, LinkedIn, and review platforms simultaneously. When a competitor gains citation share, you know within days. The sales call that used to be how you found out about a narrative shift becomes a confirmation instead of a discovery.
2. Consistency: One source of truth across every surface
When an AI system builds an answer about your product, it pulls simultaneously from your website, your G2 reviews, your documentation, your blog, your YouTube descriptions, and your LinkedIn content. 44.2% of all LLM citations come from the first 30% of text. The opening third of every page is the citation target zone. If that opening says something slightly different from the opening on your comparison page, the model reflects that fragmentation back to the buyer.
Consider what this looks like inside most organizations. Your sales team uses “AI-native.” Marketing writes “AI-powered.” Documentation says “machine learning-enabled.” Three teams. Three reasonable approximations of the same claim. An AI synthesizing your brand across those surfaces does not pick the clearest version. It averages them. The buyer receives a blurry composite that none of your three teams intended to describe, and that blurry composite becomes the foundation of a buying decision.
I spent six weeks with one company doing nothing except closing consistency gaps. No new content. No new claims. Just taking what they already knew to be true about themselves and making it say the same thing across every surface their buyers encountered. Three months later, their brand was appearing in AI answers where it had been absent. The product had not changed. The coherence had.
That kind of maintenance, done manually, never fully happens. There is always something more urgent. The surface that should have been updated eighteen months ago is still running old messaging. The fragmentation accumulates quietly, and the model averages it into something none of your teams recognize as their positioning.
The consistency Agent treats your core positioning as a single source of truth. When messaging shifts, every downstream expression updates with it: website, documentation, product pages, review responses. The fragmentation that produces blurry AI answers gets closed before it compounds into something unrecognizable.
3. Reporting: Current data for decisions that cannot wait
Only 42% of marketing teams are actively monitoring AI search visibility at all. Most of those are doing it manually, which means they are tracking what happened, not what is happening.
In a category where citation share shifts meaningfully in weeks, a six-month-old ACR report is not a lagging indicator. It is a picture of a different market entirely.
Every content investment, every budget reallocation, every messaging decision made against stale data is calibrated to a map that has already expired.
The reporting Agent pulls ACR data on a set cadence and surfaces what moved, which competitors gained ground, and which question clusters need attention, without anyone spending hours extracting and consolidating. Leadership sees the metric that actually predicts pipeline health on a regular basis, built from current data. Competitors gaining ground in the answers that matter most surface before you feel it in pipeline, not after.
4. Distribution: Citation surface area at scale
80% of URLs cited by LLMs do not rank in Google’s top 100 for the original query. The citation map looks nothing like the old link graph. Case studies and pricing pages drive the highest AI referral traffic. How-tos and guides have cratered.
Every piece of foundational content you create has downstream expressions across Reddit, LinkedIn, YouTube, review platforms, and third-party comparison sites that represent real citation surface area. Most teams produce the foundational content and execute roughly 20% of the downstream distribution. The remaining 80% is repetitive, format-specific rewriting that never quite reaches the top of the priority list.
I worked with a Series B company in data infrastructure whose SEO metrics looked strong. Good domain authority. Solid rankings for core terms. When we audited their AI answer presence across top buying questions, they were almost invisible. Not second or third. Absent. A competitor had spent two years showing up consistently across Reddit, G2, and comparison platforms, answering the same questions clearly, in the formats AI systems actually pull from.
The uncomfortable part of that conversation was not identifying the problem. It was explaining that the competitor had done nothing technically sophisticated. They had just shown up consistently in the places that mattered. There was no shortcut. Just eighteen months of work that should have started thirty-six months earlier.
Ramp did the opposite. Using Profound, they identified that AI engines were citing automation and software comparison content, exactly what their traditional SEO had deprioritized, built two pages designed for AI pickup, and generated 300+ citations in thirty days. Their Accounts Payable solution went from 3.2% to 22.2% AI visibility in a single month. One month. Two pages. 7x from a standing start.
The distribution Agent scales that motion automatically. A single piece of foundational content gets transformed into a LinkedIn thread structured for indexing, YouTube metadata written for extraction, a Reddit contribution framed for the community where the buying question actually lives. Same positioning. Built from one source. The content calendar stays the same. The citation surface area multiplies.
5. Brand governance: Quality at velocity
As content velocity increases, brand consistency is the first thing to break. Tone drifts. Legal language gets approximated. The technical differentiation that required precise language becomes a vague claim that does not survive synthesis.
An AI system pulling from dozens of approximated surface expressions does not find the clearest version. It averages the drift. Every inconsistency is a signal the model discounts the next time it builds an answer about your category.
Brand guidelines living in a PDF nobody reads are not a guardrail in a high-velocity content operation. They are a wish. At speed, after-the-fact review either slows everything down or gets skipped. At scale, both outcomes destroy the quality floor that took years to build.
The brand Agent builds your voice, legal requirements, and tone standards directly into the output layer before content ships. The guardrail is structural, not procedural. The quality floor you spent years establishing stays intact as volume increases, without the approval cycle that either creates bottlenecks or gets bypassed entirely.
What the full system actually produces
The Webflow result I opened with was not a content sprint. It was what happens when a team gets visibility into the right signals and executes consistently against them. Profound gave us that visibility: continuous monitoring across AI interfaces, weekly reporting on which buying questions we owned and which we had already lost, a clear picture of where competitors were gaining citation share before we could feel it in pipeline. We knew where to work because the data told us. The team did the rest.
That was the motion run by a disciplined human team with the right intelligence. What is different now is that the execution layer itself is agentic. Profound Agents runs each component of the Answer Ownership System continuously, without the manual ceiling that made the motion hard to sustain at the frequency the environment requires. The strategy is the same. The infrastructure executing it has changed entirely.
The scale of adoption tells you something important. Over 1,000 enterprises now run on Profound, including 10% of the Fortune 500. Target, Walmart, Figma, Ramp, MongoDB, and Plaid among them. That is not a popularity signal. It is a confirmation that the infrastructure being replaced, manual monitoring, episodic reporting, inconsistent distribution, approximated brand standards, is exactly what most teams are still running. And those teams are losing citation share every week to the ones who replaced it, in answers their buyers have already moved on from.
Deploy First. Let Agents Do the Rest.
You already know you have exposure. Every team does. The question is whether you close it with a system that runs continuously or a manual audit that is already out of date before it lands in your inbox.
The agents are built. You do not need to hire for this. You do not need a sprint. You need to pick the component most exposed in your category right now and deploy against it.
Monitoring. Consistency. Reporting. Distribution. Brand governance. One of those is where your competitors are gaining citation share while you are reading this. The agent that covers it can be running before the end of the week.
Before Profound, we found out about narrative shifts in deal debriefs. Months after the damage was done. With Profound running, we caught a competitor gaining citation share within days. Response live in a week.
That compression is the whole game.
The companies that own their categories in three years started before the loss showed up in pipeline. Most teams are still waiting for the deal debrief.
StackedGTM.AI covers AI-native go-to-market strategy for B2B operators. No frameworks for frameworks’ sake. No theory without proof. If this piece changed how you think about how buyers find you, subscribe. There is more where this came from.
If you want to see the Answer Ownership System running in practice, start with Profound. I have been genuinely impressed with what they have built specifically around AI answer monitoring and agents. Real infrastructure for a problem most teams are still solving manually. That is rare right now.