
AI Search Visibility Is a Vanity Metric
The math is right. The prompts are wrong. How to fix the input layer every AEO program is missing.

I tear down vanity in this category for a living. This one hits different.
Profound launched Prompt Research Reports last week. It is the most important release the AEO category has shipped this year and the implications will take the rest of the conversation months to absorb.
The LinkedIn vanity on AEO is (very) loud and shallow. The teams I work with are still getting the fundamentals wrong. The problem Profound just solved is the one I have been writing about, auditing, and watching operators ignore for the last 18 months. Every AEO program I have audited shares a single hidden failure mode. I have yet to find one that does not have it.
Here is what is actually going on.
Most AEO is built on fiction
Open any AEO platform. Same architecture every time. A list of prompts, a score against each one, a dashboard claiming to tell you how visible your brand is in AI Search.
The dashboards work. The math is correct.
The prompts are wrong.
Pull the tracking list out of any AEO program in production right now and it came from one of three places: SEO keywords, sales intuition, or a quick scrape of competitor messaging. None of those inputs reflect what buyers actually type into ChatGPT, Claude, Gemini, or Perplexity. Which means every visibility score in the industry right now is being calculated against prompts real users often do not actually ask.
This is the AEO equivalent of measuring conversion rate on traffic that had no purchase intent. You can produce a number. The number means nothing.
The three failure modes of current prompt selection
SEO-derived prompt lists are intent-mismatched. Search keywords and AI prompts diverge on length, specificity, and conversational structure. “Best CRM for B2B” is a search query. “I’m running a 12-person sales team selling to mid-market manufacturers and we just hit Series A, what CRM should I evaluate first” is a prompt. The first one shows up in your keyword tool. The second one is what your buyer actually typed. Tracking the first tells you nothing about whether you show up for the second.
Intuition-derived prompt lists carry sales bias. When the marketing team asks the sales team what buyers ask, they get a list of objection-handling questions. Those questions exist late in the funnel, after a buyer is already evaluating you. The 95% of the buyer journey that happens before sales sees the lead is invisible. You end up tracking the conversations you wish were happening, not the ones that are.
Competitor-derived prompt lists are a lagging indicator. Reverse-engineering your prompt set from what competitors appear to be optimizing for assumes they figured it out. They did not. They are guessing too. You are now copying their guesses and calling it strategy.
Every AEO program I have audited in the last six months has at least two of these three failure modes baked into its tracking list…and honestly, most have all three.
Why the math breaks
Pick any AEO metric. Brand visibility, citation rate, share of voice in AI answers. They all share the same structure: a percentage of prompts where your brand shows up.
The percentage depends on which prompts you measured against.
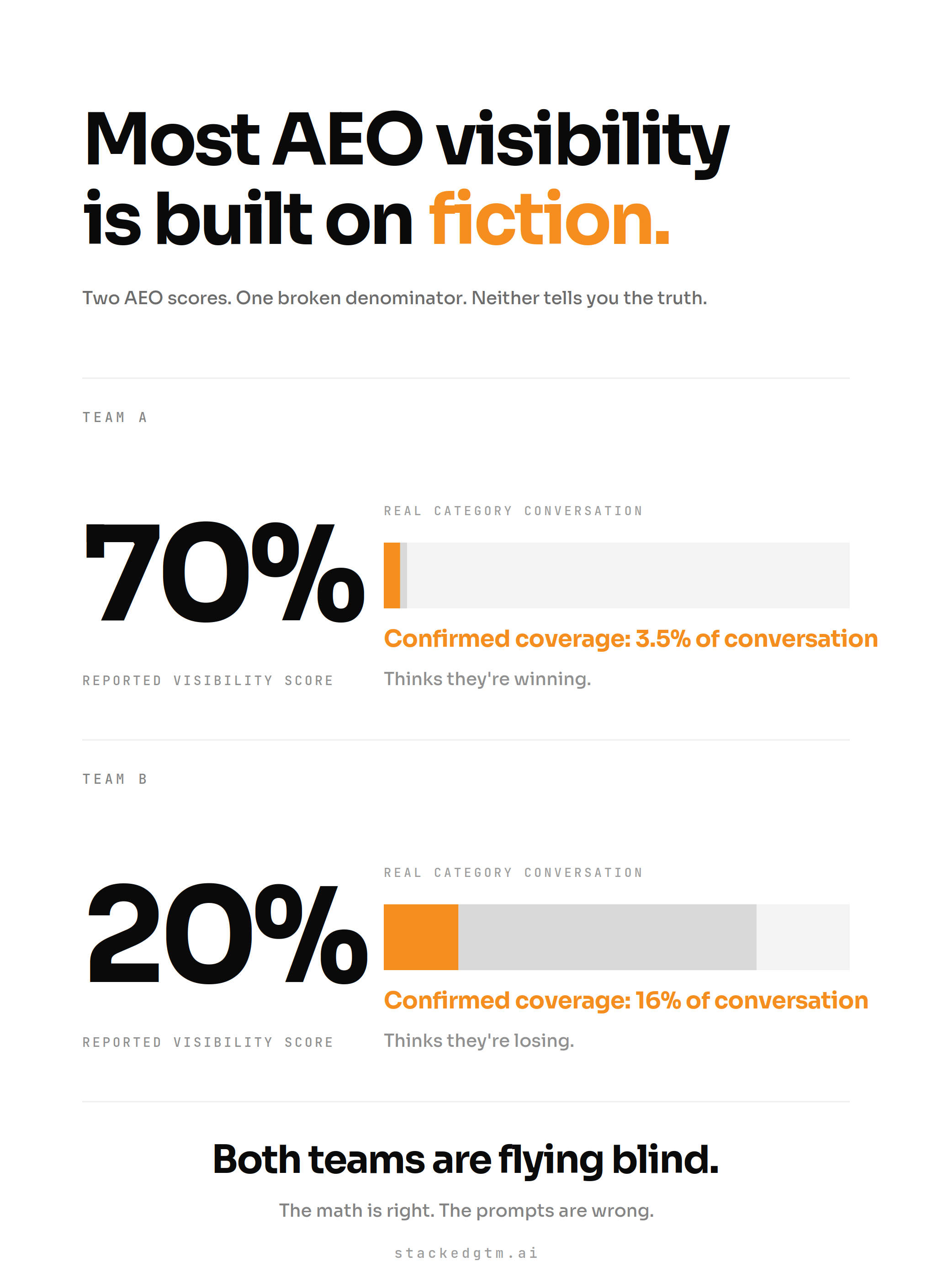
If the prompt list is wrong, the score measures something that does not exist. You can post a 70% visibility score on a prompt set that represents 5% of real conversations. You can post 20% on a prompt set that represents 80% of real conversations. The first team thinks they are winning. The second team thinks they are losing. Both are flying blind because neither one knows what the actual conversation surface looks like.
The pattern I keep seeing: most tracking lists capture maybe a quarter of real conversation volume in the category, often less. The rest of the buyer conversation is happening without you, and your dashboard has no way to tell you it exists.
This is the upstream problem nobody is solving. Every AEO conversation right now is about content optimization, citation engineering, or schema. All of that work compounds on top of prompt selection. Get the inputs wrong and the entire program is theater.
What real prompt selection looks like
The methodology has four stages. Anyone running an AEO program at scale needs to be doing this, whether they buy a tool or build it themselves.
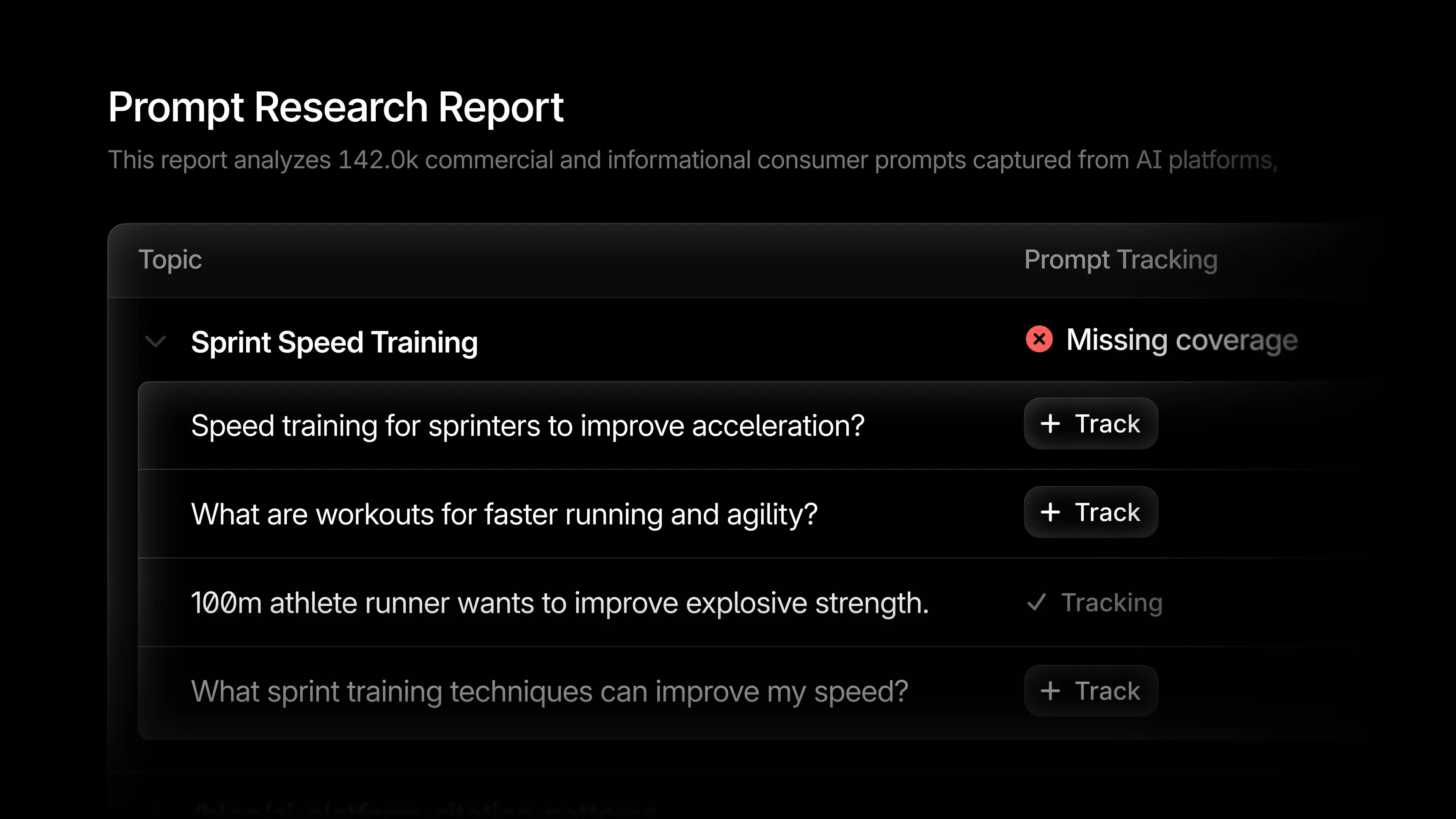
Stage one: retrieve real prompts. Not keywords. Not internal hypotheses. Actual user conversations captured from AI platforms over a recent window, semantically searched against your category and brand inputs. The volume matters. You need a corpus large enough to surface the long tail, not just the obvious head terms.
Stage two: filter and rank. Real prompt data is noisy. Duplicates, near-duplicates, off-topic drift, multilingual variants. The filtering pass matters as much as the retrieval pass. A clean corpus of 5,000 verified prompts is more useful than a dirty corpus of 500,000.
Stage three: cluster into topics. This is where a generic solution would fall short. Ask a generic LLM to cluster a thousand prompts about your category and you get one giant bucket labeled with your category name. Useful clustering requires models built to find distinctions inside a topic, not similarity across one. Each cluster needs to map to a distinct thing buyers are trying to do.
Worth flagging: how you cluster is a strategic decision, not a technical one. Slicing prompts by use case versus by buyer concern versus by journey stage produces completely different competitive surfaces. Accept the default clustering your tool produces and you have outsourced your category positioning to a generic algorithm. The teams who treat the keywords, topics, and specific descriptions they feed the tool as positioning work are the ones who get to choose how the category gets framed before the dashboard is ever built.
Stage four: select canonical prompts. Within each cluster, you do not need to track every variant. You need the prompt that best represents the cluster’s center of mass. One canonical prompt per cluster, ranked by how much of the underlying conversation volume it covers. That coverage score is the metric that matters now. It tells you how much of the real conversation surface your tracking list represents.
The output of this process is not a longer prompt list…it is a smaller, sharper one. The pattern I keep seeing: the right configuration ends up 30-50% smaller than what the team was tracking before, with coverage several times higher.
This is where the standard playbook gets it backwards. Adding more prompts to your tracking list does not make your AEO program smarter. It makes it dumber. Every low-coverage prompt you add dilutes your aggregate numbers, hides your real gaps under noise, and creates the illusion of completeness. Your dashboard looks more thorough and tells you less. The discipline is subtraction, not addition. There is still room for the prompts you want to monitor for brand intelligence reasons, including your product against named competitors, your specific business questions, or the conversations you want to know about even if they are not high-volume yet. Those belong on a separate tracking layer, not folded into your aggregate visibility score. Mixing them in is how the score becomes meaningless.
How to run this in practice
Run this as a quarterly cadence, not a one-time audit.
Quarter one: build the baseline. Run the methodology against your category and produce your initial canonical prompt set. Document coverage by cluster.
Quarter two: measure drift. AI conversation patterns shift faster than search keywords. New prompts emerge as products ship and buyers learn how to talk to LLMs. Re-run the retrieval and look for clusters that grew, shrank, or appeared.
Quarter three: tie to content investment. The intent breakdown of your prompt set tells you where to invest. Heavy informational skew means you need foundational education content. Heavy commercial skew means you need comparison content. Heavy transactional skew means you need decision-stage proof assets. The prompt set is the brief.
Quarter four: prioritize the gaps. Now that the denominator is real, your visibility score becomes a number you can actually move. Rank your highest-coverage clusters by where your brand shows up least. Those are the highest-leverage gaps in the category.
This is the operating cadence. None of the programs I have audited are running it end-to-end.
What Profound actually shipped
This is the methodology Profound just shipped in production. Prompt Research Reports run the four-stage workflow above against a proprietary corpus of over 1.5 billion real user prompts captured from AI platforms. Retrieval, ranking, clustering, canonical prompt selection. The output is your category’s prompt configuration with coverage scores and intent breakdown. You see which topics are covered, which are missing, and how your buyers split between research, evaluation, and purchase.
This is the only implementation of this methodology I have seen ship at scale. The reason that matters is not the product. It is the data underneath it.
You cannot do this work without a corpus of real prompts at volume. That corpus is not something you build in a quarter or buy off a shelf. Profound has been capturing real AI prompt data longer than the rest of the market has been measuring it. They built the dataset first, then shipped the operator-facing product on top of it. That is the right sequence and almost nobody else is in a position to copy it. And the data is only half the moat. Within-topic clustering at this scale is a genuinely hard mathematical problem in its own right. A competitor who got the corpus tomorrow would still need to ship the math, and the math is the part that takes time to get right.
What I am most impressed by is the speed. The AEO category is barely 18 months old. The infrastructure problems they are solving here are not trivial. Capturing real prompt data at volume. Building clustering models that find within-topic distinctions where general-purpose models fail. Surfacing all of it in a configuration UI operators can act on without a data science team. Shipping this now, while the category is still arguing about whether AEO is even real, is the difference between leading the category and reacting to it.
This pushes the category forward. More importantly, it ends the era of operators running AEO on intuition and calling it strategy.