
Agentic AEO
Most AEO is open-loop. Here is what closed-loop looks like, drawn from companies I am working with right now

Most teams running AEO are running it open-loop. The work ships. Nothing comes back. The citation share quietly moves elsewhere.
Last month, an advisory call. A founder pulled up his AEO dashboard. Comparison pages shipped. Case studies formatted for AI extraction. FAQ schema deployed across the site. Six months of work, executed cleanly.
I asked one question. Which buying questions are you actually winning citations for right now?
He did not have an answer. Nobody on the team did. They had been producing AEO output for half a year with no feedback loop telling them whether any of it was landing.
That call is the most common pattern I see in advisory work. Teams who have correctly identified that AEO matters. Teams executing real tactics. Teams completely flying blind on whether the tactics are landing.
The teams pulling away right now are not doing more AEO. They are running closed-loop AEO. Same tactics. Different operating layer. The difference is whether the work has feedback, measurement, propagation, and governance running continuously around it, or whether the work is being shipped into a void and called a strategy (which happens more than I’d like to admit).
Distribution without monitoring is content production with no feedback. Distribution without consistency is fragmentation at scale. Distribution without reporting is investment without measurement. Distribution without brand governance is voice drift at velocity.
AI systems absorb new narratives inside weeks. None of those gaps are recoverable after the fact. By the time you feel the loss in pipeline, the citations driving it have been live for months.
Closed-loop AEO is the only version of this work that compounds. The five agents below are what running the loop looks like in practice. This is how I build it with the companies I advise.
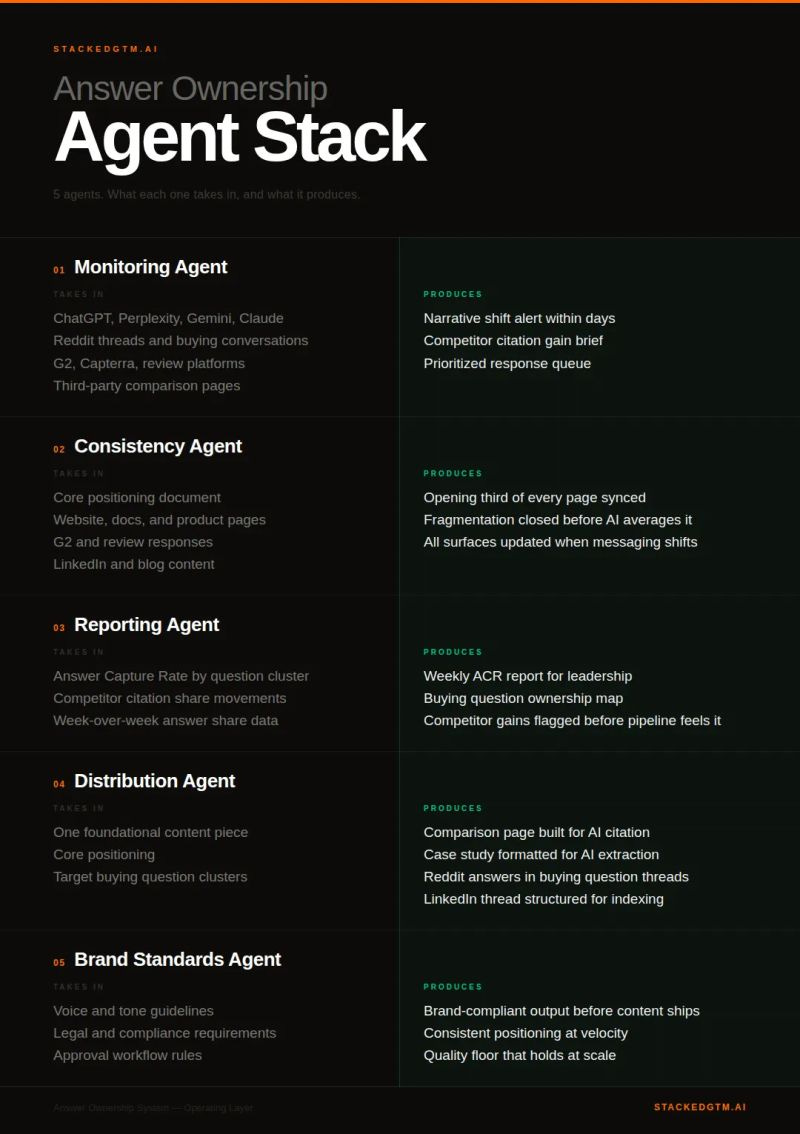
The five agents
Each one has a specific job, specific inputs, specific outputs. When one is missing, the loop opens.
1. Monitoring Agent
Takes in: ChatGPT, Perplexity, Gemini, Claude. Reddit threads and buying conversations. G2, Capterra, review platforms. Third-party comparison pages.
Produces: Narrative shift alerts within days. Competitor citation gain briefs. A prioritized response queue.
One current engagement is a Series B data infrastructure company. The team believed they owned the head buying question in their category because they had ranked first in Google for it for two years. We deployed Profound monitoring across the category, and inside the first week the actual citation map surfaced.
ChatGPT was pulling its answer from a GitHub issue thread. A former engineering customer had documented, in detail, why they had migrated to a competitor. The issue had been resolved over a year earlier. The thread was archived. To the team it felt like ancient history.
The model treated it as authoritative. Structure, technical specificity, a clear evaluation conclusion. That was enough.
You cannot make a GitHub thread disappear. The fix was a structured response covering the same evaluation criteria, published on surfaces AI systems weight more heavily. We also updated the team’s own comparison pages so the buying question got answered coherently across the category. Citation share started moving inside three weeks. Not from the new content alone. From the new content with the rest of the loop catching up around it.
The lesson is structural. Profound’s research found only 11% of domains cited by ChatGPT also appear in Perplexity. Watching one interface is not watching the category. Watching weekly is not watching the rate of change. And the surfaces AI systems actually weight are often surfaces your team has never thought to monitor.
2. Consistency Agent
Takes in: Core positioning. Website, docs, product pages. G2 and review responses. LinkedIn and blog content.
Produces: Opening third of every page synced. Fragmentation closed before AI averages it out. Every surface updated when messaging shifts.
44.2% of LLM citations come from the first 30% of text. The opening third of every page is the citation target zone. When I run a positioning audit for a new advisory client, this is almost always where the largest gap is.
A recent audit, Series A fintech. The website described the product as serving three categories. The documentation grouped the same functionality into five. The G2 listing used a sixth taxonomy entirely. An AI synthesizing the brand across those surfaces could not tell whether the company shipped three products, five, or six, and which problems each one solved. The buyer received a blurry composite that did not match what any single team had written.
Here is the part that surprises operators when I name it. The consistency agent is not a content tool. It is an organizational coherence tool. The reason positioning fragments across surfaces is that no single team owns the coherence question. Marketing owns the website. Product owns the docs. Customer marketing owns G2. Each is locally consistent. The composite is incoherent. The agent does not fix that. It surfaces it. The fix is operator work. The agent makes it impossible to keep ignoring.
3. Reporting Agent
Takes in: Citation share by buying question cluster. Competitor citation share movements. Week-over-week answer share data.
Produces: Weekly citation share report for leadership. Buying question ownership map. Competitor gains flagged before pipeline feels them.
Reporting is the agent everyone agrees they need and almost no one builds. The reason is that tracking citation share movement week over week feels closer to financial controllership than to marketing work. It rewards a different mindset. Adversarial reading. Pattern recognition across noisy data. The discipline to act on small movements before they become large ones. Most marketing teams are not staffed or wired for that.
The founder I opened with had no measurement layer because no one on his team had built one. They were not doing AEO wrong. They were doing AEO without a scoreboard.
When I work with a team I push reporting into the loop early, before we expand distribution. In a category where citation share moves in weeks, a quarterly snapshot is not a lagging indicator. It is a different market entirely. Every budget decision made against stale data is an expensive guess.
4. Distribution Agent
Takes in: One foundational content piece. Core positioning. Target buying question clusters.
Produces: Comparison pages built for AI citation. Case studies formatted for AI extraction. Reddit answers in buying question threads. LinkedIn threads structured for indexing. FAQ schema for direct answer surfacing.
This is the agent most teams are already running. It is also the only one most teams are running.
At Webflow, the distribution work my team executed produced +331 AI citations across our top buying questions from one specific intervention. Structured FAQ and schema designed for AI extraction. Documented in case studies, reproducible in any team’s environment. That number was not the result of more content. It was the result of foundational content being formatted for the citation map AI systems actually pull from.
80% of URLs cited by LLMs do not rank in Google’s top 100 for the original query. The citation map is wider than the link graph. Most teams are still building for the link graph and wondering why the answers form without them.
5. Brand Standards Agent
Takes in: Voice and tone guidelines. Legal and compliance requirements. Approval workflow rules.
Produces: Brand-compliant output before content ships. Consistent positioning at velocity. A quality floor that holds at scale.
As distribution velocity increases, the brand floor cracks. Tone drifts. Legal language gets approximated. Technical claims that required precise wording become vague approximations that do not survive synthesis.
The non-obvious thing about brand drift at velocity is the direction it drifts. It does not drift random. It drifts neutral. Every approximation pulls the language one click toward what generic AI-generated content sounds like. Specific claims become directional ones. Sharp positioning becomes “leading provider.” The differentiation that took three years to articulate sands down to industry-standard phrasing one shipped piece at a time.
Brand guidelines living in a PDF nobody reads do not hold against this gravity. After-the-fact review either creates a bottleneck or gets bypassed. The brand standards agent moves the guardrail into the output layer, before content ships.
Its job is not to enforce a tone document. Its job is to hold the line against the specific gravity of generic.
What open-loop AEO actually costs
Most teams running “AEO” are running Distribution alone and calling it a strategy. The tactic is sound. The problem is what is missing around it.
Three things happen in a team running open-loop AEO.
The first is that competitor narrative shifts get absorbed by the model before the team notices. By the time the loss surfaces in pipeline, the citations driving it have been live for months. Damage control on positions never known to be lost.
The second is that the team’s own positioning fragments across surfaces faster than they can track. Every shipped piece adds another approximation. The model averages. The buyer gets the average. The team produces more content, the average gets blurrier, and the citation share quietly moves to whichever competitor’s positioning is coherent across surfaces.
The third is the most expensive and the least named. ROI for AEO investment is invisible without the reporting layer. AI search drives a buyer who arrives post-synthesis, shortlist already forming, and the team often credits direct or organic for the resulting deal. The work that is actually compounding gets defunded by the team’s own measurement gap. Budget moves away from the highest-leverage motion in the stack because no one built the instrumentation to see it.
Open-loop AEO has a diagnostic. If you cannot answer three questions in under sixty seconds, you are running it. Which buying questions are you winning citations for this week. Which competitor is gaining citation share fastest right now. What shipped this week with positioning your sales team has not signed off on. If any of those answers is “I would have to find out,” the loop is open at that point. That is the agent to deploy.
Where I start with a new engagement
The deployment path is not all-or-nothing. The first move is diagnostic.
If the team has no idea which buying questions they are winning across their top 20, the gap is Monitoring and Reporting. Deploy those before doing anything else. Every subsequent investment is calibrated to data that does not exist yet. Continuous monitoring is what I deploy first here, because the gap closes in days, not quarters.
If they can name the questions they own but their messaging across surfaces is fragmented, the gap is Consistency. Close it before producing more content. Volume on top of fragmentation accelerates the averaging problem.
If foundational content is strong and monitoring is in place but downstream surface area is thin, the gap is Distribution. Build for the citation map.
If they are shipping fast and the brand floor is starting to crack, push Brand Standards into the output layer. Not into a PDF.
Two operator opinions on sequence that I will name because they are not standard advice.
First, I do not deploy Distribution until Reporting has been running for at least two weeks. Teams who write new content before they can see the citation map optimize against the wrong questions. They produce a comparison page for the question they assume matters and miss the question that is actually moving against them in the answers. Two weeks of reporting changes the brief.
Second, I deploy Brand Standards last, not first. Most consultants put governance first because it feels like the foundation. It is not. You need to see what is actually shipping at velocity before you can govern it intelligently. Brand standards built before the system runs become the same dead PDF nobody reads. Built after two months of real output, they are operational.
The single agent whose absence is currently costing the most is the agent to deploy this week. Not all five at once. The one whose gap is the most expensive.
What closed-loop looks like running
When the loop is closed, the team stops finding out about competitor narrative shifts in deal debriefs. They catch the citation gain inside a week and respond inside another. Positioning across surfaces stays coherent because consistency is structural, not aspirational. Citation share shows up in the leadership report alongside pipeline because it is the leading indicator pipeline is now lagging. Distribution scales without burning out the content team because the agent is doing the format-specific rewrites. The brand floor holds because governance is in the output layer, not the review process.
This is the configuration the teams pulling away are running. The infrastructure to do it at scale exists. Over 1,000 enterprises now run on Profound, including 10% of the Fortune 500. That is not a popularity signal. It is a confirmation that the manual operation most teams are still running is the operation those teams have already replaced.
The teams still running open-loop AEO will not feel the gap for another two quarters. By then the citation share has already moved. The deal debrief will explain why.
The loop is the motion. Everything else is content production.
StackedGTM.AI covers AI-native go-to-market strategy for B2B operators. No frameworks for frameworks’ sake. No theory without proof. If this changed how you think about how the work has to actually run, subscribe.
If you want to see the Answer Ownership Agent Stack running in practice, start with Profound. Real infrastructure for a problem most teams are still solving manually. It is what I deploy first when monitoring is the gap.