
3 AEO Automations. Steal Them.
The agent-first systems actually winning AI search right now.

One drove 94% share of voice growth and a 6x conversion lift at Webflow. One helped Docebo build a 25% category share of voice lead. The third is the closed-loop system almost nobody has built yet.
Steal all three.
A buyer in your category opened ChatGPT this morning. Typed something like “best [your category] platform for a Series B SaaS company.” Got three names back. Closed the tab.
Your website never loaded. Your funnel never started. Your sales team never got the ping.
That moment left no analytics event. No Salesforce record. No form fill. And it happened dozens of times today across your category. The shortlist was built before you knew anyone was looking.
Most teams find out six weeks later when pipeline gets weird and nobody can explain why.
I have seen a lot of AEO content this year. Most of it tells you what to do. Optimize your schema. Get on Reddit. Publish more. That is all true. It is also completely manual in a game that moves 40 to 60 percent per month on citation volatility alone, per citation monitoring data across thousands of tracked queries. You cannot outrun that by hand.
The teams quietly pulling ahead are not doing more AEO. They are building systems that do AEO for them, continuously, while they sleep. Here are a few of them, and the exact prompts to build them.
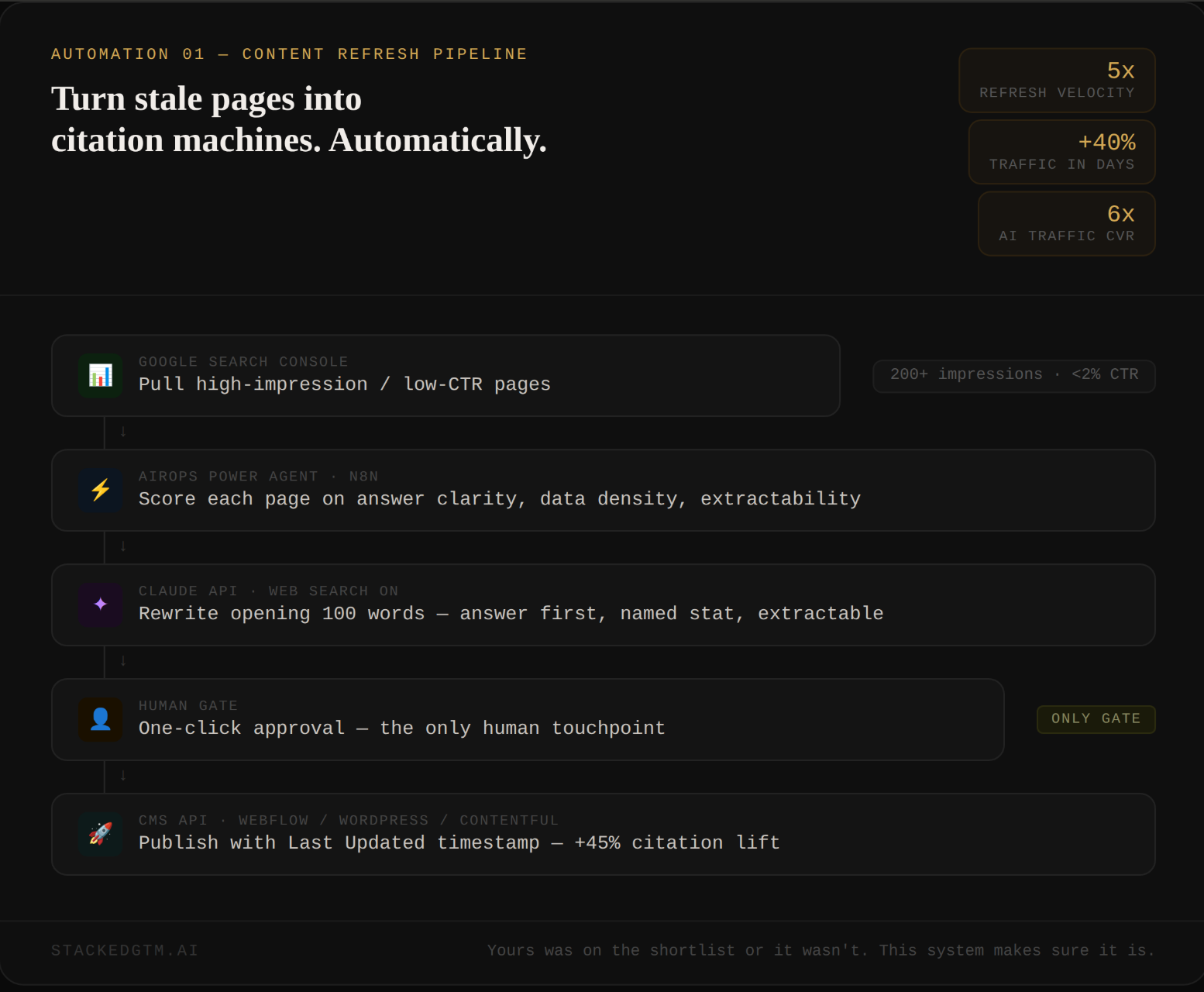
Automation 1: The Content Refresh Pipeline
Here is the number that reframes this whole thing.
According to BrightEdge and Amsive research across millions of AI responses, ChatGPT only cites 15% of the pages it actually retrieves. The other 85% get found and skipped. Your content can be indexed, crawlable, and technically excellent and still lose every time. Being retrieved is not the same as being cited.
The reason most content loses is structural, not strategic. Analysis of LLM citation patterns shows 44.2% of all citations come from the first 30% of a piece of content. The opening, not the conclusion. If your page builds context before it answers, the agent moves on before it ever reaches your best material. Adding one named statistic improves AI visibility by 41%, according to Princeton and Georgia Tech’s 2024 GEO study. Per AEO citation research, pages updated in the last three months are cited twice as often as older ones.
Those three facts together are a workflow.
I have written about our Webflow work publicly. The AirOps case study documents the results: 5x content refresh velocity, 40% traffic uplift within days, AI-sourced signups growing from 2% to nearly 10%, AI-referred visitors converting 6x higher than non-branded organic. A separate AirOps recap put the share of voice growth from LLMs at 94% during the same period.
No new content strategy. No headcount. A pipeline that rewrote the opening of each target page to lead with the answer, injected one named data point, and pushed the update straight to the CMS. Human review as the only gate.
Here is exactly how to build it.
Pull your target pages from Google Search Console. Filter for queries with over 200 impressions and under 2% CTR. These are pages Google is already surfacing where AI is eating the click before it happens. Take the top 20 URLs and run this prompt in Claude with web search on, or drop it into an AirOps Power Agent or n8n Claude API node directly:
Visit [URL].
Score the opening 150 words on three criteria:
1. Does it lead with a direct answer (not context, not setup, the answer)
2. Does it contain a specific statistic with a named source and year
3. Can the opening be extracted without surrounding context and still make
complete sense
Score each 1 to 10. Then rewrite the opening 100 words to score 10 on all three.
Rules:
- Keep the existing brand voice
- Do not add claims not already supported in the body of the page
- First sentence must be the answer, not a question or a scene-setter
- Statistic must include source name and year inline, not in a footnote
Return the three scores with one-sentence explanations, then the rewrite.Wire this as a workflow. URL list from GSC in. Claude rewrite via API. Approved rewrites push to your CMS automatically. The only human touchpoint is a one-click approval. Add a visible Last Updated timestamp every time the pipeline publishes. Per AEO citation research, this single metadata change moved citation rate from 42% to 61% in controlled testing. Do it every time, on every page.
Schedule it to re-run monthly on your top 50 pages. Not because you will remember to. Because the workflow will.
AI did not rewrite the rules for content. It just raised the bar for clarity, structure, and freshness. Automated enforcement of that bar is the whole game.
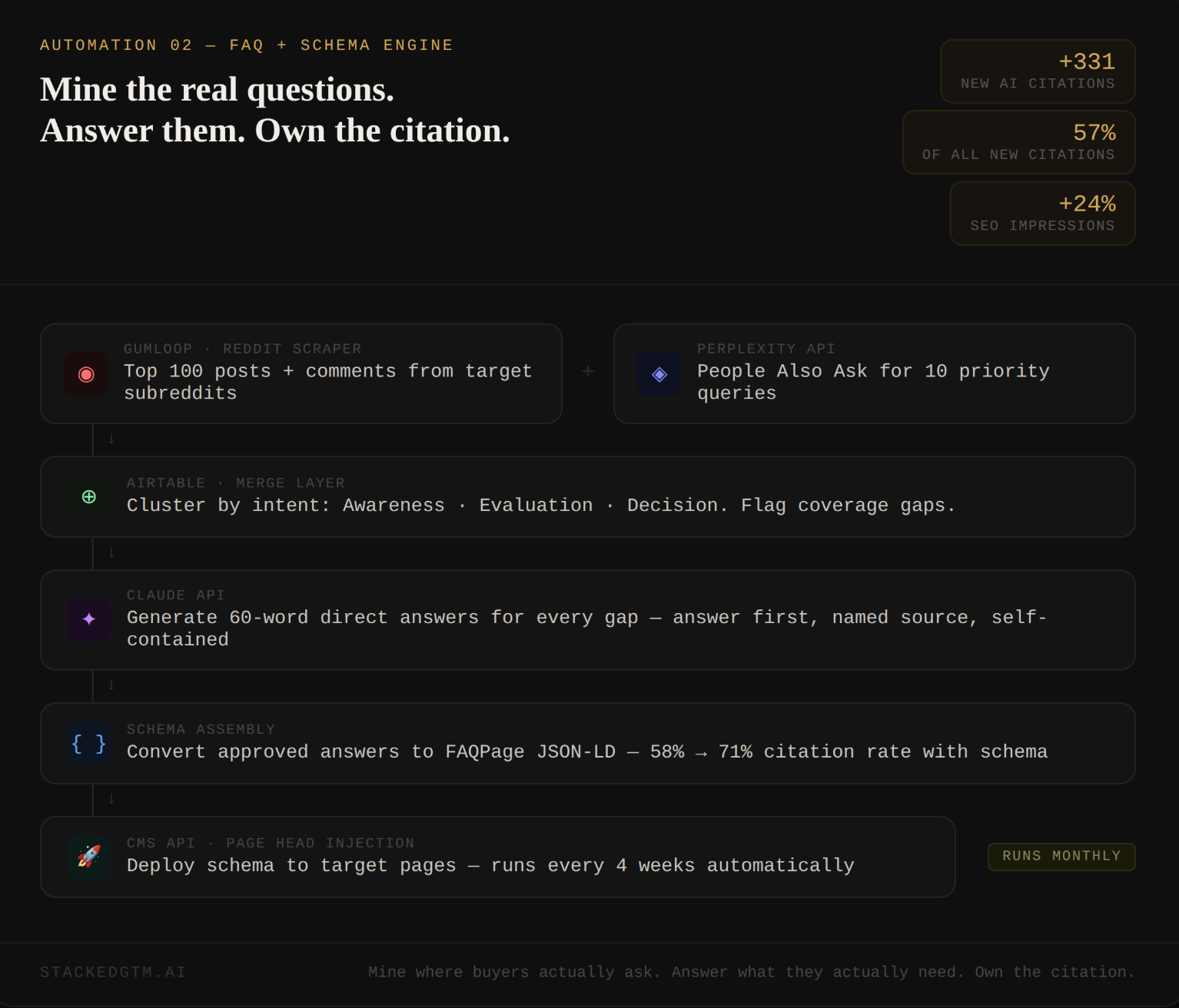
Automation 2: The FAQ Plus Schema Engine
I have shared it publicly before.
Six Webflow product pages: Design, CMS, SEO, Shared Libraries, Interactions, Hosting. The workflow pulled real questions from People Also Ask, niche subreddits, and community forums simultaneously. Claude generated on-brand answers to the gaps. Those answers were structured into FAQPage JSON-LD and injected directly into each page.
The results:
331 new AI citations. 57% of all new citations on the domain that period. 149,000 additional SEO impressions. A 24% increase versus the prior period.
No hype. No AI buzzwords. Just structured answers to real questions people actually ask, delivered in a format AI engines are built to extract.
Per analysis of 2,000-plus cited pages across platforms, FAQ-heavy content with proper FAQPage schema achieves a 71% citation rate versus 58% without it. Without schema, the agent infers what your page answers. With it, you hand it a machine-readable instruction set. That 13-point gap is entirely structural and it is free to close.
The thing most teams get wrong is sourcing. Marketing teams write FAQ sections based on questions they think buyers are asking. Those are not the questions buyers type into AI engines at 11pm trying to solve a problem. The gap between those two sets of questions is where citations go to die.
Want to go deeper on question mining? I wrote the Definitive Guide to Questioning Mining here.
In Gumloop, drop in their Reddit Scraping node, zero configuration required. Point it at your two or three most relevant subreddits and pull the top 100 posts and comments. Separately, use a SERP API (SerpAPI and DataForSEO both have dedicated PAA endpoints) to pull Google’s People Also Ask boxes for your ten priority queries. Merge both outputs into Airtable, then run this:
Here is a list of questions pulled from Reddit and People Also Ask for [category].
1. Cluster by buyer intent: Awareness, Evaluation, Decision
2. Within each cluster, identify the five questions appearing most frequently
across both sources
3. For each of those 15 questions, check our content at [URL] and flag:
- Answered directly
- Answered partially
- Not answered
4. For every Partially Answered and Not Answered question, write a 60-word
direct answer:
- First sentence is the answer, not a lead-in
- Include one specific data point with a named source
- Must make complete sense without surrounding context
- No hedging language
Return as a table: question, intent stage, coverage status, answer draft.Run approved answers through this before touching schema:
Edit this FAQ answer for FAQPage schema deployment:
[paste answer]
Requirements:
- Under 80 words
- First sentence is the answer
- One specific data point with named source and year inline
- Self-contained (someone reading only this understands it fully)
- Reads like a knowledgeable human wrote it
Return only the edited answer. No explanation.Then generate deployment-ready JSON-LD:
Convert the following FAQ pairs into valid FAQPage JSON-LD schema
following schema.org specifications.
[paste question and answer pairs]
Format:
- Valid JSON-LD in a <script type="application/ld+json"> tag
- Each FAQ as a Question entity with acceptedAnswer
- Full answer text, no truncation
- Ready to paste into a page head with no further editing needed
Return only the schema block.Paste that block into your page head. If you are on a platform without custom code access, the workflow outputs a handoff file engineering can implement in ten minutes.
Schedule the full workflow every four weeks. New questions surface constantly. The automation catches them. You do not have to.
The playbook is simple: use data on the questions people are actually researching, create content that answers them clearly, and structure it so AI engines can surface it with precision. The workflow just makes that repeatable.
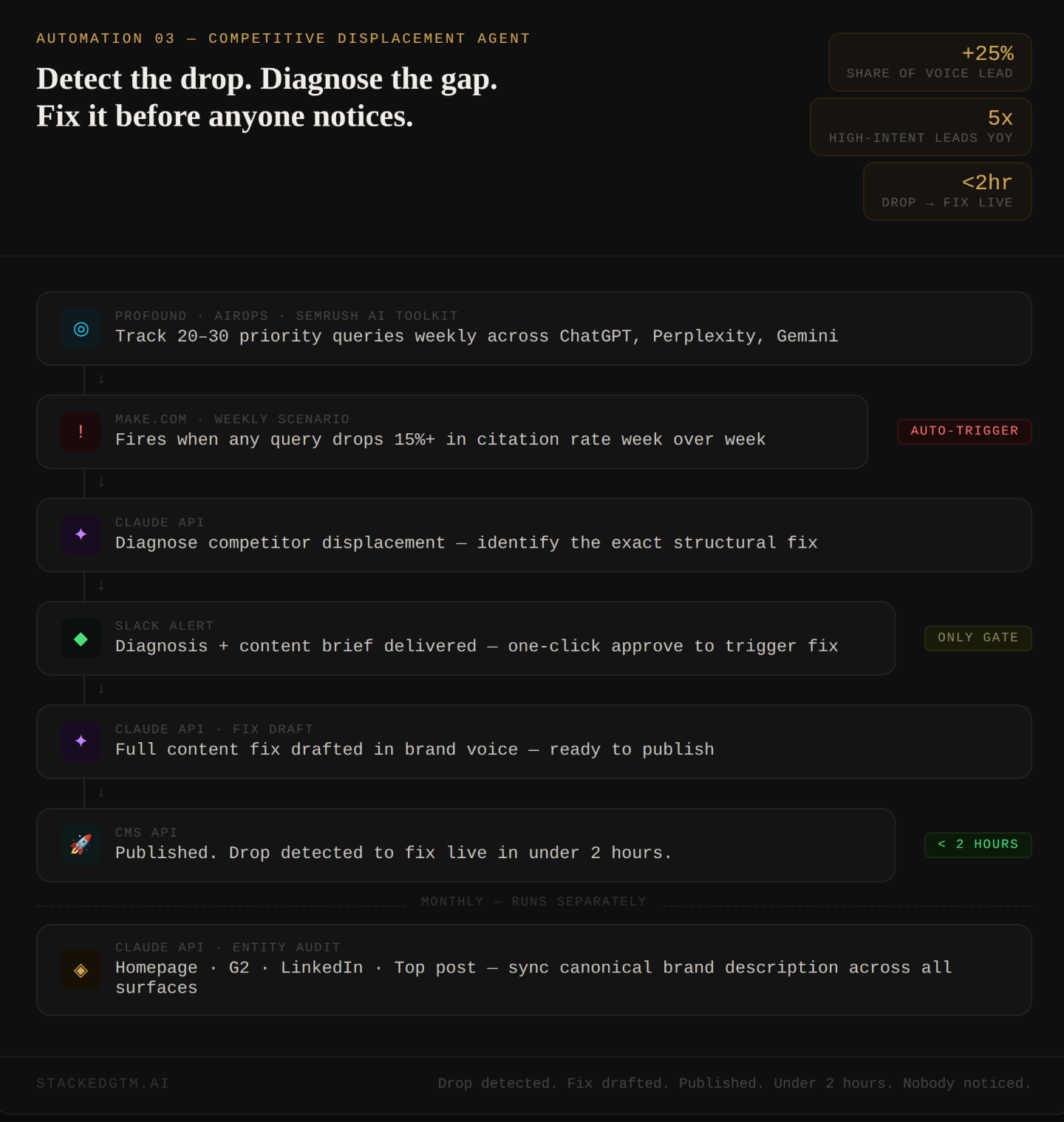
Automation 3: The Competitive Displacement Agent
This is the one almost nobody has built yet.
Per Yext analysis of 6.8 million citations across platforms, only 11% of domains are cited by both ChatGPT and Gemini. Per BrightEdge research, 80% of the URLs being cited right now do not rank in Google’s top 100. Citation volatility runs at 40 to 60 percent monthly, per citation monitoring data across thousands of tracked queries. By the time your quarterly review catches a drop, it has been compounding for weeks.
Manual monitoring fails at the speed this moves. You need a closed loop.
Docebo is a learning management platform in a crowded enterprise software category. They built systematic tracking of AI share of voice and automated response to competitive displacement across their content library. The results AirOps documented: a 25% share of voice lead in their category, with AI discovery driving 12.7% of high-intent leads, up 5x year over year.
Not from a content sprint. From a system.
In Profound, AirOps, or Semrush’s AI Visibility Toolkit, configure tracking for 20 to 30 priority queries, the exact questions your buyers type when evaluating your category. Run your first full pull. Save every response. That is your before-state. Everything from here is measured against it.
In Make.com, build a scenario that pulls citation data weekly via your tracking tool’s API. Set one condition: if any tracked query drops 15% or more week over week, the scenario fires. When it fires, it passes this to the Claude API:
A citation drop was detected.
Brand: [brand]
Query: [query]
Drop: [X]% week over week
Current top-cited pages: [URLs and titles]
Our current content: [URL]
1. Diagnose why competitors are being cited instead of us:
- Does their opening answer the question more directly
- Do they have a comparison table we are missing
- Do they cite more recent or specific data
- Are their sections shorter and more extractable
- Is their schema more complete
2. Identify the single highest-leverage fix
3. Write a specific content brief:
- What exactly changes and where on the page
- The first sentence of the fix as a model
- Any specific data point to add with suggested source type
Return: diagnosis in two paragraphs, brief in bullet points. Under 300 words.That diagnosis routes to Slack. One-click approve fires a second call that drafts the full fix and pushes it to your CMS:
Using the diagnosis and brief below, draft the content fix for [URL].
Diagnosis and brief:
[paste output from above]
Current content at the relevant section:
[paste existing section]
Rules:
- Match existing brand voice exactly
- Do not introduce claims not supported on the page or in public sources
- Fixed section must open with a direct answer
- If a comparison table is recommended, build it, do not describe it
- Output ready to paste into the CMS
Return only the replacement content. No preamble.Citation drop detected. Competitor identified. Fix drafted. Published. Under two hours. Nobody had to notice it happened.
Once a month, run the entity audit. Feed Claude your homepage, G2 profile, LinkedIn company page, and most-cited blog post:
I am giving you four descriptions of [brand] from different surfaces.
Homepage: [paste]
G2 profile: [paste]
LinkedIn company page: [paste]
Most-cited blog post intro: [paste]
Analyze for entity consistency across:
- How we describe our product category
- How we describe our ideal customer
- Our primary differentiator
- The use case we lead with
For each inconsistency:
1. Name the specific conflict
2. Explain in one sentence what citation damage it causes
Then write:
- A 75-word canonical brand description optimized for AI entity clarity
- The exact copy update for each surface to bring them into alignment
Return as: Inconsistencies, Canonical Description, Surface Updates.Per AEO citation research, brands earning both citations and mentions are 40% more likely to resurface consistently across multiple AI responses than brands earning mentions alone. Entity drift, where your brand gets described differently across surfaces, is one of the most common and least diagnosed reasons citation rates plateau. One prompt, once a month, run automatically. It catches drift before it compounds.
The winners of AEO right now are not the best content teams. They are the best systems thinkers.
These three automations are not three separate tactics. They are one ecosystem. The refresh pipeline keeps your content citation-ready. The FAQ engine keeps your answers sourced from where buyers actually ask. The displacement agent closes the loop when competitors move. Each one compounds the other. None of them work as well in isolation.
Agents are making this job both easier and more complex at the same time. Easier because the execution layer — the research, the rewrites, the schema, the diagnosis — can now run without you. More complex because the game is no longer about publishing good content. It is about building infrastructure that responds faster than any manual team can. The brands figuring that out right now are building leads that will take competitors years to close.
The buyer who opened ChatGPT in your category this morning got three names back. Yours was either one of them or it wasn’t.
78% of marketing teams have no way of knowing which. Per Averi.ai analysis of AI referral data, the traffic coming through that channel converts at 14.2% versus Google organic’s 2.8%. The highest-intent buyers in your funnel are arriving through a channel most teams cannot see, let alone defend.
These three systems fix that. Not eventually. This week.
Build the first one. Let it run. Then build the next.
Building one of these workflows this week? Reply and tell me which one. I read every response.
Josh Grant Founder, StackedGTM.AI | Ex-VP Growth @ Webflow | Ex-Affirm
This is a meaty one. Really solid - love the concrete examples and templates. I'm going to be testing these out. Thanks, Josh!